Link to Project Proposal training materials
Project Name:
- Proposed name for the project: SO
- Proposed name for the repository:
so
Project description:
The SO provides the highest level of service orchestration in the ONAP architecture. Currently SO is implemented via BPMN flows that operate on Models distributed from SDC that describe the Services and associated VNFs and other Resource components. Cloud orchestration is currently based on HEAT templates.
In order to support Use Cases 1 and 2 in such a way to promote re-usability within ONAP, the goal of this project is to enhance ONAP’s overall orchestration capabilities by aligning and integrating its imperative workflows with a TOSCA-based declarative execution environment.
Service Orchestrator in ONAP WIKI
- This project proposes an expansion of ONAP SO to include a declarative topologically-driven approach to orchestration. Specifically this project proposes to enhance ONAP SO run-time orchestration framework to support orchestration driven from declarative models (TOSCA encoded) as well as integrated or independent BPMN imperative processing extensions that themselves could be TOSCA-aware.
This is envisioned as a multi-release project, which in its maturity will:
- Support TOSCA models in native format as distributed by SDC
- Perform lifecycle operations based on a declarative TOSCA model, including:
- Deployment
- Undeployment
- Scale (Out, In)
- Heal
- Software Upgrade (various forms)
Alternative 1: The following diagram illustrates one option for the internal processing BPMN and TOSCA Orchestrator sub-components within SO. In this approach a separate off-the-shelf TOSCA Orchestrator is incorporated into SO, with a top level BPMN layer delegating well defined orchestration activities to this native TOSCA Orchestrator (see diagram below).
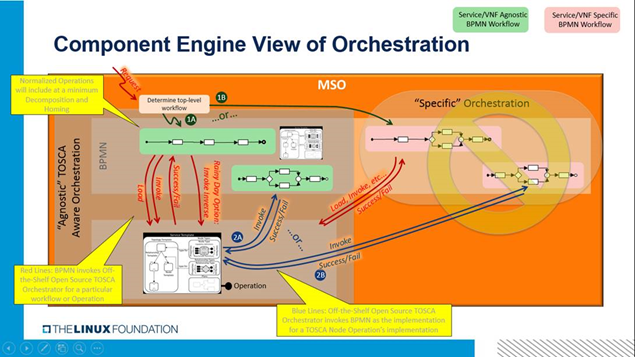
Alternative 2: Another potential approach is shown below, where the BPMN itself in effect is a TOSCA Orchestrator component.
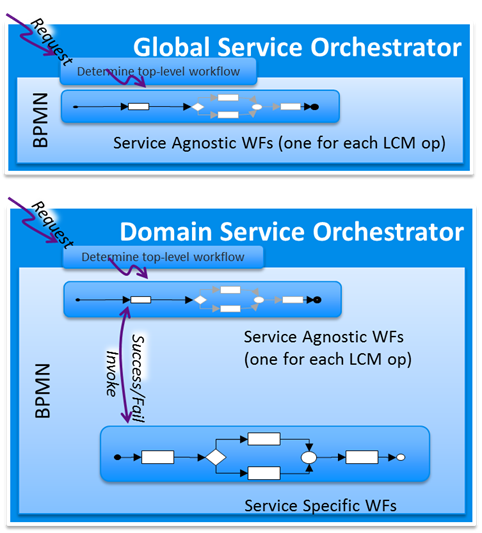
It is envisioned that initial Releases of this project would demonstrate both alternative approaches:
For Alternative 1 approach:
- Demonstrate SO BPMN workflows interacting with an off-the-shelf TOSCA Orchestrator to collectively drive orchestration behavior for at least an instantiation use case
- Demonstrate rainy day handling
- Accomplish the above in a way that is demonstrably extensible to support lifecycle operations such as Scale-In and Scale-Out.
For Alternative 2 approach:
- Demonstrate SO BPMN workflows to drive TOSCA-aware orchestration behavior for VoLTE use case, dependency to VF-C.
- Support lifecycle operations such as Scale-In and Scale-Out.
Architecture Alignment:
- How does this project fit into the rest of the ONAP Architecture?

What other ONAP projects does this project depend on?
SDC (true dependency with SDC SDK)
AAI (using API interface)
SDN-C (using API interface)
APP-C (no existing interface yet)
DMaaP (included as part of SDC SDK)
- MSB (no existing interface yet)
VF-C (no existing interface yet)
- Multi-VIM (no existing interface yet)
How does this align with external standards/specifications?
- TOSCA Simple Profile in YAML Version 1.0
- OASIS TOSCA Simple Profile for Network Functions Virtualization (NFV) Version 1.0
- Are there dependencies with other open source projects?
- ARIA
- JBOSS
- Camunda
- MariaDB
- EELF
- Resources:
- Primary Contact Person: DeWayne Filppi (dewayne@gigaspaces.com), Xin Jin (saw.jin@huawei.com OPEN-O R2 GS-O PTL), Steve Smokowski, ss835w@att.com (AT&T MSO PTL)
- Names, gerrit IDs, and company affiliations of the contributors:
- DeWayne Filppi, dewayne@cloudify.co Cloudify
- Byung-Woo Jun - byung-woo.jun@ericsson.com Ericsson
- Xin Jin saw.jin@huawei.com Huawei
- Chuanyu Chen chenchuanyu@huawei.com Huawei
- Seshu Kumar, seshu.kumar.m@huawei.com Huawei - at ONS 2018
- Steve Smokowski, ss835w@att.com AT&T
- Rob Daugherty, rd472p@att.com AT&T
- John Choma, jc1348@att.com AT&T
- Gil Bullard, gil.bullard@att.com AT&T
- Ting Lu, tl2062@att.com AT&T
- Jeff Mitryk, jm5764@att.com AT&T
- Claude Noshpitz, cn5542@att.com AT&T
- Eric Debeau, eric.debeau@orange.com Orange
- Christian Destré, christian.destre@orange.com Orange
Lingli Deng denglingli@chinamobile.com CMCC
- Chengli Wang wangchengli@chinamobile.com CMCC
- Anbing Zhang zhanganbing@chinamobile.com CMCC
- maopeng zhang zhang.maopeng1@zte.com.cn ZTE
- Joe Zhang, zhang.zhou1@zte.com.cn, ZTE
- Jinhua Fu fu.jinhua@zte.com.cn ZTE
- Jie Feng feng.jie2@zte.com.cn ZTE
- Li Jiang li.jiang@zte.com.cn ZTE
- Tian Yi tian.yi@zte.com.cn ZTE
- Hui Deng denghui12@huawei.com Huawei
- Thinh Nguyenphu, thinh.nguyenphu@nokia.com, Nokia
- Yan Yang yangyanyjy@chinamobile.com CMCC
- Ni Lu mail luna.lu@huawei.com Huawei
- Bin Hou mail bin.hou@huawei.com Huawei
- Hrvoje Kegalj hrvoje.kegalj@hr.ibm.com IBM
- Ethan Lynn ethanlynnl@vmware.com VMware
- Earle West ew8463@att.com AT&T
- Zhou Jun mail zhoujun8@huawei.com Huawei
- Heliu Zhong zhongheliu@boco.com.cn
- Yuanwei Yang yangyuanwei@boco.com.cn
- Victor Morales, victor.morales@intel.com Intel
- Steve Baillargeon, steve.baillargeon@ericsson.com Ericsson
- Names and affiliations of any other contributors
Project Roles (include RACI chart, if applicable)
Name Email ID Specific expertise (if any) contributing area of Interest in SO Role % of Effort Location Catherine Lefèvre
Belgium UTC +2
Alex Vul
USA UTC-8
Tal
tal@gigaspaces.com Chicago, IL, USA UTC -5
DeWayne Filppi dewayne@gigaspaces.com TOSCA, Python, Java, Aria Option 1 path 100% LA, CA, USA UTC-8 Tal Liron tal@gigaspaces.com TOSCA, Python, Java, Aria Option 1 path 50% Byung-Woo Jun - byung-woo.jun@ericsson.com Xin Jin saw.jin@huawei.com Java, Orchestration, BPMN Option 2 path Chuanyu Chen chenchuanyu@huawei.com Java, Orchestration , BPMN Option 2 path Seshu Kumar seshu.kumar.m@huawei.com BPMN, TOSCA, Python, Java, orchestrator engines Decision point and option 2 path Steve Smokowski ss835w@att.com Rob Daugherty rd472p@att.com John Choma jc1348@att.com Gil Bullard gil.bullard@att.com General orchestration model driven orchestration Ting Lu tl2062@att.com Meta data model creation in SDC to Drive SO execution Define design artifacts to feed SO Observer Jeff Mitryk jm5764@att.com Claude Noshpitz cn5542@att.com Eric Debeau eric.debeau@orange.com Christian Destré christian.destre@orange.com Lingli Deng denglingli@chinamobile.com Usecase & Requirements Usecase Requirements Breakdown Chengli Wang wangchengli@chinamobile.com Anbing Zhang zhanganbing@chinamobile.com Infrastructure as a Service Integration with Multi-Cloud maopeng zhang zhang.maopeng1@zte.com BPMN, TOSCA, orchestrator engines option 2 path Joe Zhang zhang.zhou1@zte.com BPMN, orchestrator engines option 2 path, adapter between SO and VFC Jinhua Fu fu.jinhua@zte.com Jie Feng feng.jie2@zte.com Li Jiang li.jiang@zte.com Tian Yi tian.yi@zte.com Hui Deng denghui12@huawei.com Modeling spec Alignment of modeling spec? Thinh Nguyenphu thinh.nguyenphu@nokia.com Yan Yang yangyanyjy@chinamobile.com Ni Lu mail luna.lu@huawei.com Java, Orchestration, BPMN Option 2 path 30% Bin Hou mail bin.hou@huawei.com Hrvoje Kegalj hrvoje.kegalj@hr.ibm.com Ethan Lynn ethanlynnl@vmware.com Core reviewer of OpenStack Orchestrator project(HEAT)
Core reviewer of OpenStack Clustering project(SENLIN)Adapter between SO and MULTIVIM if it exists. Earle West ew8463@att.com Zhou Jun mail zhoujun8@huawei.com Observer Heliu Zhong zhongheliu@boco.com Yuanwei Yang yangyuanwei@boco.com Victor Morales
victor.morales@intel.com
Other Information:
- link to seed code (if applicable)
https://gerrit.onap.org/r/#/admin/projects/mso
https://gerrit.onap.org/r/#/admin/projects/mso/chef-repo
https://gerrit.onap.org/r/#/admin/projects/mso/docker-config
https://gerrit.onap.org/r/#/admin/projects/mso/libs
https://gerrit.onap.org/r/#/admin/projects/mso/mso-config
- Vendor Neutral
- if the proposal is coming from an existing proprietary codebase, have you ensured that all proprietary trademarks, logos, product names, etc., have been removed?
Subsequent modification to the existing seed code should continue to follow the same scanning and clean up principles. - Meets Board policy (including IPR)
Use the above information to create a key project facts section on your project page
Key Project Facts
Project Name:
- JIRA project name: Master Service Orchestrator (can be renamed as Service Orchestrator)
- JIRA project prefix: MSO- (can be renamed as SO-)
Repo name: mso (can be renamed as 'so' ?)
Lifecycle State:
Primary Contact:
Project Lead:
mailing list tag [Should match Jira Project Prefix]
Committers:
Rob Daugherty, rd472p@att.com, AT&T
John Choma, jc1348@att.com, AT&T
DeWayne Filppi dewayne@gigaspaces.com, GigaSpaces/Cloudify
Tal Liron tal@gigaspaces.com, Gigaspaces/Cloudify
Xin Jin saw.jin@huawei.com
Byung-Woo Jun byung-woo.jun@ericsson.com Ericsson
Chuanyu Chen chenchuanyu@huawei.com
Seshu Kumar, seshu.kumar.m@huawei.com
Joe Zhang, zhang.zhou1@zte.com.cn, ZTE
Maopeng Zhang zhang.maopeng1@zte.com.cn, ZTE
Lingli Deng denglingli@chinamobile.com CMCC
Chengli Wang wangchengli@chinamobile.com CMCC
Anbing Zhang zhanganbing@chinamobile.com CMCC
Yan Yang yangyanyj@chinamobile.com CMCC
Heliu Zhong zhongheliu@boco.com.cn
Yuanwei Yang yangyuanwei@boco.com.cn
Ethan Lynn ethanlynnl@vmware.com VMware
*Link to TSC approval:
Link to approval of additional submitters:
47 Comments
Lingli Deng
Hi, thanks for the proposal. Sorry for missing the drafting session. I have the following comments:
1, Would you clarify what you mean by "Use AAI and TOSCA node requirements to perform late service/infrastructure binding"?
2, Would you clarify what you mean by "MSO Catalog representation of the TOSCA"?
3, The diagram used for "the ONAP Architecture" is not a complete picture only a subset of it.
DeWayne Filppi
Eric Debeau
Thanks for the proposal. I have a few questions:
DeWayne Filppi
Can't speak authoritatively re: 1. Yes, ARIA is envisioned as the TOSCA workflow engine for the first release, with the caveat that BPMN would be the upstream and downstream workflow mechanism, per the overall architecture. Re: 3 I'm hoping that there is no direct binding to any internal service (including model storage), rather just protocols on a message bus. Time will tell.
Eric Debeau
Why open-o is considered as the seed code for the project ? We never decided such choice during the discussions.
Brian Freeman
Byung-Woo, How does the APPC/VF-C functions for Heal and Software upgrade fit into SO role in the architecture ? This seems like overlap did you mean to just include the Instantiate/Terminate/Scale functions. Heal and software upgrade wouldn't be done through SO.
DeWayne Filppi
I'll chime in; Byung-Woo may have a different opinion. I think the interpretation was that the app controllers fulfill a role similar to VNFM in the ETSI MANO concept; where as the MSO is roughly equivalent to the NFVO in the same. On the other hand, if app controllers essentially do everything, then the MSO appears to only function as a message queue between BPMN and controllers.
Brian Freeman
Steve Smokowski correctly reminded me that I was forgetting HEAT stack updates which SO does today. I was thinking of the internal VNF software upgrades/patches that APPC does (e.g. scripted changes from vendor to patch their application not changing the cloud layer). HEAL is still a potential overlap since we have two distinct software upgrade paths (both should be driven by CMO) - one that is at the cloud layer and one that is inside the vnf application/vfc.
DeWayne Filppi
OK good. Definitely healing going on at multiple levels potentially.
Rob Daugherty
MSO is the seed code base, not open-o GSO. I've removed the reference to GSO.
HuabingZhao
I have a couple of questions:
1. Alternative 1 uses an "off the shelf" orchestrator for TOSCA declarative orchestration. Does it mean that the orchestrator is an external component such as Aria and we will not able to modify the source codes of the "off the shelf" orchestrator? Why I have this question is because that I can't see how Aria can support the VoLTE use case which needs interactions with SVNFM.
2. Assuming SO delegate a TOSCA service template that consists of multiple VNFs connected by VLs, How the "off the shelf" orchestrator update the instance to A&AI after each VNF/VL is created?
3.From the project description of APPC, It seems that APPC intends to be a VNFM to handle the Lifecycle Management of VNF, including create, update, configure and delete. So what's the relationship of the "off the shelf" orchestrator" and the APPC? Will it delegate the LCM of VNF to APPC?
DeWayne Filppi
HuabingZhao
So in that case, the "install" workflow is a custom imperative workflow written in python, is there any big difference between an imperative workflow written in python and in BPMN or other languages?
DeWayne Filppi
No. Python is not a requirement, implicit or otherwise. Aria happens to be written in Python, but that is an implementation of a specific engine, not a system requirement (implicit or otherwise). I imagine a Python-based orchestrator would access the BPMN engine (Camunda or otherwise) using its REST API, if directly invoking workflows. Hopefully the MSB project provides a message based interface between projects that avoids such bindings however. That would mean that all bindings between the orchestrator and BPMN (either input or output) would be via the MSB, and Camunda would be a consumer and producer of messages for interested collaborators.
jin xin
Hi All:
I suggest that we should also demonstrate Alternative 2 approach in the Release 1.
The details is following:
For Alternative 2 approach:
I think it's better to achieve ONAP R1 goals on time.Thanks.
DeWayne Filppi
Unless you're suggesting a change to alternative 2, I see no TOSCA at all in there. Alternative 1 is the blending of TOSCA and BPMN as you suggest. I agree with scale in and scale out, although a look at the VF-C proposal and it seems to be automating the entire ETSI MANO stack, leaving little if anything for SO to do. Need clarification there; perhaps the TSC will provide it.
jin xin
Thank you for your reply.
In my opinion,The alternative 2 should define some tasks about the tosca model parser and workflow processes in the top-level bpmn workflow..
For example?the first task parses the service template from SDC. The second task generates the directed graph base on the parser data.The third task executes the directed graph.
maopeng zhang
I suggest that we should also integrate with the VF-C in the VoLTE case, so the VF-C should be added as dependancy.
DeWayne Filppi
Looking at VF-C, I'm not sure what that would look like. It appears to be doing everything (or almost everything) the SO has proposed to do. I think the many orchestrators are overlapping in ways that don't make sense.
maopeng zhang
Orchestrator in my mind is not one layer, and should be multi-layer. Higher orchestration is incharge of E2E service orchestration, cross-domain service, integrated with other domain orchestration, such as SDN orchestrator or NFV domain orchestrator. The domain orchestrators also maybe be mutiple in different clouds. I think the higher orchestration and the domain orchestration are not overlapping and it is really the SP's requirement.
DeWayne Filppi
All, the proposal has been submitted as of the Friday deadline.
Catherine Lefevre
Hi Dewayne,
I have added the seed repo as well as the major open source dependencies since the current SO source code has been integrated with several open sources.
Do I need to add the complete list?
I believe that Aria will be added to the existing SO framework to support TOSCA?
Catherine Lefevre
I have also added a comment regarding the Vendor Neutral section.
Suggested tools or anything else equivalent: FOSSology, Blackduck suite, Sonar, CheckMarx
Xiaojun XIE
Hi, guys,
I have a question about the definition of end-to-end service in SO. Does it refer to RFS (Resource-Facing Service defined in TMForum) or NS (Network Service defined in ETSI NFV)?
If it refers to RFS, TOSCA may not be commonly used. Task-Driven Workflow may be more suitable for this, especially for the services supporting multiple customers.
If it refers to NS, SO would overlay with VF-C, because VF-C also implements the TOSCA parsing for NS. At the same time, how do ONAP implement RFS orchestration? Or, is it not in the scope of ONAP?
jin xin
Hi All:
I have updated the SO project proposal to demonstrate both alternative approaches.Please review and correct me.
Thank you.
Catherine Lefevre
I also would like to consider the following JIRA items as part of this proposal if these are not solved earlier:
https://jira.onap.org/browse/MSO-4
https://jira.onap.org/browse/MSO-2
MSO-6 - Getting issue details... STATUS
MSO-7 - Getting issue details... STATUS
MSO-10 - Getting issue details... STATUS if the epic is approved (COMMON-10)
MSO-1 - Getting issue details... STATUS
MSO-9 - Getting issue details... STATUS
DeWayne Filppi
Sorry for the long silence; have been on vacation. I'm reluctant to endorse putting specific bug reports for the seed code into this document. It seems to me that requirements level statements would be more appropriate (that perhaps refer to specific Jiras); and then those requirements be evaluated by the group.
Catherine Lefevre
Good morning DeWayne, these are indeed user stories to be evaluated as part of the new SO project or can be kept as part of SO backlog or simply to be closed if no interest.
DeWayne Filppi
OK, my vote would be:
MSO-4: no
MSO-2: no
MSO-10: yes, but in some far flung release.
MSO-1: not sure what these are, and provided link doesn't work for me.
MSO-9: sure, but pretty low priority.
Catherine Lefevre
Hi Dewayne, I understand. Nevertheless the SO PTL will need to deal with the JIRA ticket.
Here is the query to identify any SO tickets:
Getting issues...
Hui Deng
In order to have unified modeling in the ONAP, it would better that SO projects depends on modeling project for example, service template, service component modeling, workflow modeling, Parsers et al.
DeWayne Filppi
Hui, I had that in there at one time but it was removed early on. I don't object to the explicit reference. I think the argument against was that the actual software dependency was with the SDC. How the SDC represents the orchestration template (and related workflows) will determine much.
DeWayne Filppi
JBoss was included as a requirement due to the seed code. What are group opinions regarding JBoss (or Wildfly I guess), JEE in general (I'm not a fan), or at least eliminating JBoss as a project requirement?
Catherine Lefevre
If you decide to remove JBoss then what will be your alternative?
DeWayne Filppi
I think I was off base here. I was viewing the JBOSS reference as a system requirement, not simply a fact of life in the seed code. At this point, I would not remove it. If starting from scratch I'd use something lighter like Guice or Spring. I worked in JBoss (and other JEE platforms) for years, and grew to despise them.
maopeng zhang
what's the exact scope of the "off-the-shelf TOSCA Orchestrator" ?
DeWayne Filppi
Orchestrating native TOSCA templates. Essentially, the same function as the generic MSO workflows.
maopeng zhang
Could we called it "tosca workflow engine", not orchestrator? Orchestrator concept may cause some confusion.
If it is an worklflow engine, what's the tosca grammars that the workflow engine depends on? How does it integrate with the SO in the software layer? could you provide the workflow api specificaiton for community? Thanks.
Seshu Kumar Mudiganti
DeWayne,
As discussed in the F2F meeting, kindly find the points for clarification as they are critical for realization of the proposed design:
DeWayne Filppi
DeWayne Filppi
Additional response for item 3. At present, my intent is to model A&AI and Controllers as entities in the TOSCA model, access via their APIs via plugins (Python), because that's probably the fastest way to success.
DeWayne Filppi
Everyone, please note that the TSC has indicated that only 2 committers can be listed for each company. Please edit the list as appropriate.
Manoj Nair
Couple of queries
1) If I understand correctly, now heat template is distributed from SDC to SO. Also VF-C expects a TOSCA based model. In this case, SDC is expected to distribute two types of artifacts? One for SO for instantiating VFs and other TOSCA templates for VF-C to consume?
2) In Open-O there used to be a mechanism to provide a workflow link as part of the Plan as described here - https://wiki.open-o.org/display/IN/Nanjing+Workshop+August+9-11,+2016#NanjingWorkshopAugust9-11,2016-CommonTOSCA. Will this capability be supported for enabling imperative workflows. Also in this case will SDC be capable of distributing the workflow file and SO be capable of handling such workflow artifacts?
3) Is there validation done at SO for the heat template received from the SDC?
4) How is the NS state reconciled currently? Is there any polling mechanism in place to synchronize the state of NS? Or this is purely based on the DCAE Control loop capability?
DeWayne Filppi
1) I'm working the TOSCA path and am hoping the SDC will provide CSARs. My understanding that the SO orchestrates services, not VNFs. As such, the SO will want TOSCA models that deal with VNFs at as high a level as possible (location, interconnection, etc..). The VNFs themselves may consist of several compute instances and have their own independent lifecycle management (per CLAMP), and need their own TOSCA models. I don't think we want a service designer role to be penetrating the VNF abstraction at all; they should be black boxes (i.e. a vIMS by company X version Y with certain capabilities). That's just my understanding though. Much of this can be derived from the desired end user experience, be it service designer or VNF vendor.
2) No. In TOSCA the model implies the workflow, at least ideally. There will be a generic workflow that ultimately hands off to the TOSCA orchestrator, and will gather information needed by the orchestration (e.g. Homing/OF, possibly some A&AI stuff, and more (TBD)). We've had discussions about having southbound BPMN flows tied to TOSCA operations, but that's not needed (or happening) in R1.
3) Not sure about the BPMN side, but the TOSCA side doesn't care about (or want) HEAT, just TOSCA/CSAR, so no need to dumb down TOSCA.
4) NS?
Manoj Nair
Thanks for the clarifications DeWayne. Couple of follow up questions
#1 : Can you please share the wiki link for this work.
#2 : So does it mean that SO will have a Cloudify engine capable of receiving the TOSCA models from Catalog and processing it ? In one of the SO calls there were discussions around having multiple TOSCA parsers in SO (which is not available currently) - one for imperative workflows and other for declarative TOSCA models. Is this plan holds good for R1 ?
#3 : I believe NS state (Active, InActive, Maintenance etc) is maintained in A&AI and my understanding is that SO in collaboration with DCAE is responsible for reconciling the state of NS based on the VNF events received. Is this understanding correct.
Sunil Kumar
Hi,
I am looking into CreateE2EServiceInstance workflow . I am able to locate Api ( SO -> VFC ) from it . But as per the workflow , Api url is different from the mentioned SO api list in
wiki.
Api url found from above workflow -> /vfc/rest/v1/vfcadapter/.. ( during Create NS )
SO Api as per wiki /api/nslcm/v1/ns
How both are being mapped ??
Hao Kuang
Hi,
I am just wondering where can I put any bug or question about so?