Overview
This analysis is to see the possibility of scaling the CPS-NCMP component horizontally to respond well to increased load.
CPS-786
-
Getting issue details...
STATUS
Scenario
Load scenario: (model)sync 10,000 cm handles with the same schema-set: imagine this is done by firing 1000 requests of (batches of) 10 cm handles registration to a pool of cps-ncmp instances
CPS Deployment in ONAP
Currently, CPS in ONAP deployment has the following configuration shown in the table below.
**Resources listed below is only relevant for this study
| Resource name | Description | Notes |
|---|
| cps-and-ncmp deployment | - creates instances of pods (set of containers) that run cps application
- default pod replica count is set to 1 (i.e. creates 1 pod)
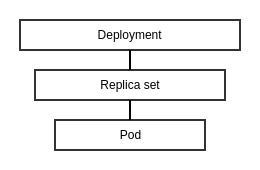
| - replica count can be changed to the number of pods desired to be added through values.yaml file of the cps-core component
- the value 'replicaCount' is used by the deployment object configured in the manifest deployment.yaml
- deployment.yaml
- apiVersion: apps/v1
kind: Deployment
metadata: {{- include "common.resourceMetadata" . | nindent 2 }}
spec:
replicas: {{ .Values.replicaCount }} - . . .
-
- if the replica count is 2, the deployment object will create and k8s controller ensures that the number of running pods is always 2, the load is also distributed among the replicas
- this method has been tested to create 3 instances of cps-ncmp by specifying replicaCount in values.yaml
- values.yaml
- . . .
# Resource Limit flavor -By Default using small
flavor: small
# default number of instances
replicaCount: 3
# Segregation for Different environment (Small and Large)
resources:
. . .
|
| postgres deployment | - creates instances of pods that run Postgres
- default Kubernetes pod replica count is set to 1 (i.e. creates 1 pod)
- utilizes persistent volumes
|
|
| cps-core service | - enables network access to pods running cps application
- uses the default service type 'ClusterIP' which exposes CPS's multiple ports to allow only internal access to pods
- this service is also exposed by an Ingress which exposes HTTP and HTTPS routes from outside
- operates with an Ingress resource wherein the traffic rules are stated
- allows the service to be reachable via URL
- allows multiple services to be mapped to a single port
| - Other service types are NodePort, LoadBalancer, and ExternalName
- 'ClusterIp' service type uses round-robin/random to load balance
- i.e. increasing the number of pods results in the request being sent to a random pod
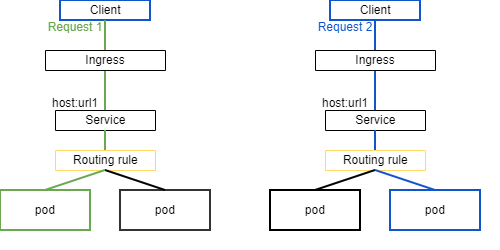
|
| postgres Service | - uses the default service type ClusterIP
- ingress is not enabled for this service therefore it is only accessible within the Kubernetes cluster
|
|
In the case, that for one instance of the service and it's seen that bottleneck comes from the connection pool size, this can be configured to change from the default size of 10.
CPS application runs with Spring Boot and by default, the DataSource implementation that comes with this, and on CPS, is HikariCP. Therefore, to modify the maximum pool size from 10 ,the yaml file 'application.yaml' in cps-application folder can be updated to add maximum pool size definition.
Example:
.....
spring:
.....
datasource:
url: jdbc:postgresql://${DB_HOST}:1234/cpsdb
username: ${DB_USERNAME}
password: ${DB_PASSWORD}
driverClassName: org.postgresql.Driver
initialization-mode: always
hikari:
maximum-pool-size: 20
**The following change on the example above has been tested and passes all CSIT tests and is deployable.
Load Balancing Options
| Load balancing option | Description | Issues | Possible solution |
|---|
Increasing pod/replica count via deployment object - This method has been tested on minikube to create 3 instances of cps-ncmp
- Each pod were monitored through logs
- one specific pod accomodated majority of the requests
- one pod did not accept requests at all
- as client, received correct responses
| Replica count is changed from the default number to the number of pods desired to be added through values.yaml file - Defined in the manifest deployment.yaml which means the deployment object created will own and manage the replicaSet
- this is the recommended way to use replicaSets
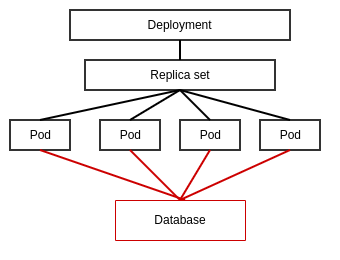
| - Burst propagation
- eviction of one replica results in the load being redirected to another replica
- CPU in the node can be/will be fully used up
| - adding a Horizontal Pod Autoscaler (HPA)
|
Database Bottleneck | ****can be a different study on how to scale Postgres horizontally - Vertical Scaling
- more resources such as CPU and memory are added
- Postgres horizontal scaling (Sharding)
- Slices tables into multiple smaller tables (shards) wherein each will be in run on different database
- ***Feedback from Renu Kumari
- Based on the reasons below, Bell decided not to work on scaling the database at the moment:
- Postgres charts used by CPS uses 'deployments' instead of 'stateful' sets
- Complex task
- Changing the current Postgres charts will impact other components
- ONAP also have an initiative to separate services from the storage.
|
| Using Horizontal Pod Autoscaling | - allows the automatic deployment of pods to satisfy the stated configuration wherein the number of pods depends on the load
- i.e. the workload resource will be scaled back down if the load decreases and the number of pods are above the configured minimum.
- HPA can be defined with multiple and custom metrics.
- metrics can be customized so that HPA only scales on HTTP requests
- metrics can be customized so that HPA only scales on Ingress requests per second
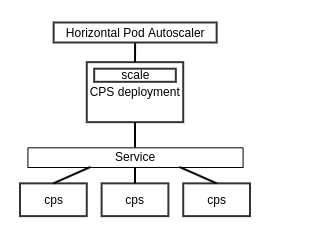
| - HPA scales up and distributes workload efficiently over the replicas with the linearly increasing workload but takes time to scale up or down with bursty workloads
| - Configure sync period
- the default interval is 15 seconds
|
- Would require changes/updates to the current CPS deployment resources
| - Remove 'replica' variable in cps-and-ncmp deployment manifest
- deployment.yaml
- apiVersion: apps/v1
kind: Deployment
metadata: {{- include "common.resourceMetadata" . | nindent 2 }}
spec:
replicas: {{ .Values.replicaCount }}
- . . .
- Add a manifest to create a HorizontalPodAutoscaler object
- sample HPA manifest
- apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: cps-and-ncmp
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: cps-and-ncmp
minReplicas: 1
maxReplicas: 10
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: cps-core-ingress
target:
type: Value
value: 100 .... - Might need to add a separate service to support monitoring metrics
- service needs to implement custom.metrics.k8s.io or external.metrics.k8s.io
|
References:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://www.gsd.inesc-id.pt/~mpc/pubs/smr-kubernetes.pdf
https://www.heydari.be/papers/WoC-stef.pdf
http://bawkawajwanw.com/books/masteringkubernetes.pdf
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#:~:text=In%20Kubernetes%2C%20a%20HorizontalPodAutoscaler%20automatically,is%20to%20deploy%20more%20Pods.
https://www.heydari.be/papers/WoC-stef.pdf
https://www.weave.works/blog/how-to-correctly-handle-db-schemas-during-kubernetes-rollouts
https://www.diva-portal.org/smash/get/diva2:1369598/FULLTEXT01.pdf
https://www.percona.com/blog/2019/05/24/an-overview-of-sharding-in-postgresql-and-how-it-relates-to-mongodbs/
https://momjian.us/main/writings/pgsql/sharding.pdf