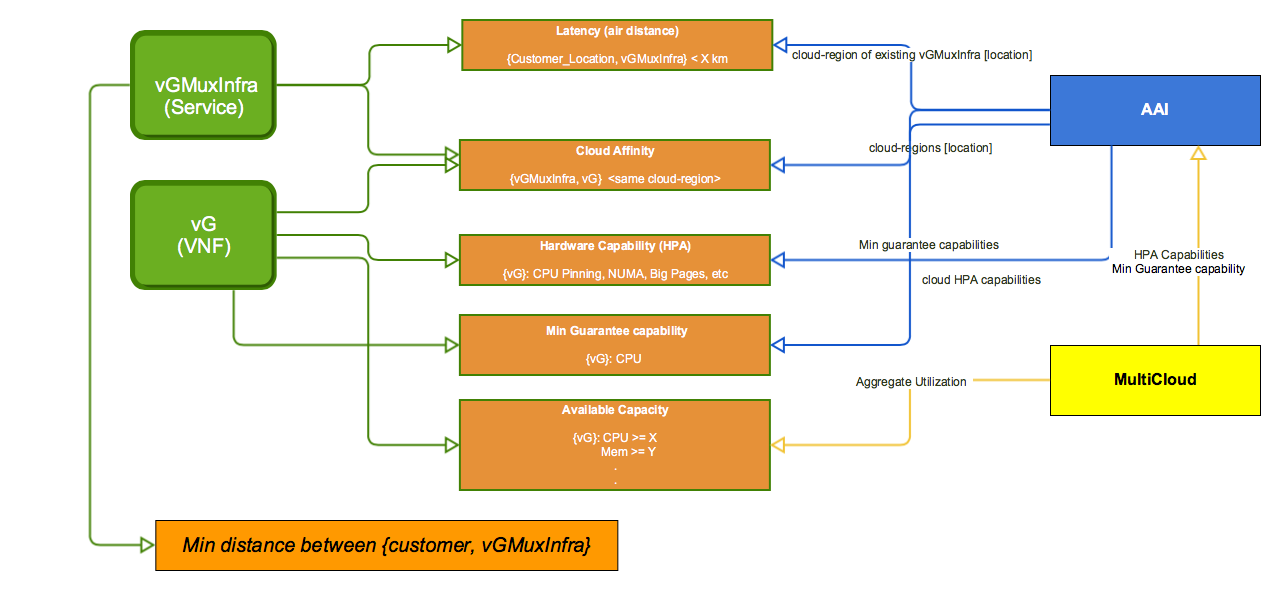
The homing service while determining the placements of the service, performs the match-making between the VNF's hardware requirements, and the hardware capabilities that are provided by the VIMs. These vendor requirements are captured as policies in the Policy framework and consumed by OOF to be used when determining the placements. Similarly, the hardware capabilities provided by the VIM instance (cloud-region) is exported to AAI by MultiCloud, and is consumed by OOF from AAI.
The proposal for persisting and retrieving HPA attributes related to a cloud-region from AAI can be found here: Persistence of HPA related information in AAI
Gap discovered in a deep dive discussion: Homing happens at the VNF level, while Homing need to map flavors at the granularity of VFModules.
Collecting the discussion from multiple threads [need to organize this better once we reach a workable solution]
The current data model in AAI looks like the following:
cloud-region1 → flavor1 → [HPA1, HPA2]
cloud-region1 → flavor2 → [HPA3]
Assumption is that there will be a one-to-one mapping between a VNF and a flavor.
Consider a scenario where a VNF spans two VMs, one of which needs HPA1, HPA2 and the other needs HPA3. Now, would VNF be represented as two resources that need to be homed? Is it always true that there will be only one flavor that a VNF needs to map onto?
Therefore, either
(i) VNF cannot expect to have its requirements across two flavors, or
(ii) The assumption of homogeneity may require that there be a flavor with a super set of all capabilities that a cloud-region supports in which case we will end up with one flavor per cloud region (cloud-region1 → flavor3 → [HPA1, HPA2, HPA3, HPA4, HPA5]), or
(iii) requires the creation of multiple flavors that captures the different combinations of capabilities, which is a combinatorial problem.
- One NSD (Network Service Descriptor) can contain multiple VNFs.
- Each VNF can contain
- Multiple VDUs (VNFCs)
- Internal Virtual Links
- Internal Connection points
- Connection points to External Links.
- Each VDU (VNFC) is normally realized as one VM or set of scale-out VMs.
Each VDU is defined with HPA properties that are required for that VDU.
An example:
Let us say that a NSD has 2 VNFs. Each VNF has 4 VDUs.
I believe OOF is passed with NSD by SO or VF-C.
OOF is expected to determine right region and flavor to use for each VDU. In above example, I would assume that OOF returns total of 8 regions and one flavor for each region (8 flavors) back to SO.
Having said that, many times, a VNF consists only one VNFC (one VDU). At least I did not see any real deployment example where a VNF contains multiple VNFCs (VDUs). Hence, people tend to equate VNF with VNFC (VDU). But, TOSCA NFV specification do have ability to represent a VNF with multiple VDUs.
In any case, it is good for OOF to assume that a VNF contains multiple VDUs.
HPA feature set filter is for each VDU. So is, distance filter.
But affinity, anti-affinity are at the scope of VNF and NSD.
Typical affinity/anti-affinity rules are as follows:
- Across VDUs of VNF (Few VDUs of VNF be on the same compute node, or in the same rack or at the edge in case of affinity rules or separately in various compute nodes, various racks or edges).
- Across VNFs of NSD ( Few VNFs of NSD in the same compute, rack or edge in case of affinity or separately in case of affinity rules, or in different places in case of anti-affinity rules).
That is why, I think SO needs to pass massaged NSD with VNFs and VDUs of VNFs together for placement decisions based on affinity/anti-affinity policy rules. Passing the VNF by SO is not good enough if OOF intends to make placement decisions based on affinity and anti-affinity rules.
Follow up discussion on the above from 02/19/2018:
- VDU specific hardware requirements using policies: It is agreed that OOF OSDF and HAS don't have any restrictions on the representation of HPA capabilities of a given VDU in one policy or set of policies. This is up to the entity creating the policy records.
- Specifying HPA capability mandatory requirements and score/weight in case of optional: OOF infrastructure and HAS infrastructure does not interpret the HPA capabilities and attributes and it is up to the HPA filter implementation in HAS. Introducing 'is_mandatory' and 'weight' attributes along with version and hwArchin of each HPA capability is okay with the OOF team.
- VNF and VDU (VFModule) : OOF, at this time, does not have a way to return the region and flavor for each VDU back to the SO. OOF, at this time consider the entire VNF as one entity and return one region and one flavor. There are two ways to address this.
- SO to decompose the VNF (with Multiple VDUs) and provide list of VDUs in its request to OOF and OOF to make placement decisions for each VDU independently and provide region & flavor for each VDU back to the SO. This is right thing to do, but it may not be possible in R2 time frame.
- Second option is to put a restriction that each VNF in TOSCA having only one VDU in it. We thought that if option (b) is chosen, it needs to be brought to architecture subcommittee for approval.
- Performance: There are multiple filters in OOF and more filters can be added in future. If each filter run independent of others, the performance can take a big hit if there are large number of regions in the A&AI. In 5G, we are thinking that there could be 5000 cloud regions (due to edge clouds) and X number of filtering going through all 5000 edge clouds for each VDU placement decision is costly. It is confirmed today that OOF does not run all filters simultaneously. These filters are executed in sequential fashion. Order of filters that are executed are at this time based on a configuration file and hence is fixed. Each filter is given set of regions as candidate list and each filter is expected to return subset of regions as output. One filter output is given as input to the next filter. That way, only the first filter may work on all 5000 regions and but subsequent filters act on only subset of the regions. In summary, each filter takes the candidate region list and outputs the subset of regions that satisfy policies of that filter.
- Filter priorities are currently based on the configuration file. In future, execution time of each filter will be considered to change the order of future filter execution. Shankar mentioned that some ML based algorithms can be used too to dynamically change the order.
- Usage of aggregate labels for HPA features such as "VM Sizes" and "Instance types" and "Openstack flavors" in policy instead of individual HPA capabilities as requirement: Ramki brought this point. OOF team said that there is no limitation in OOF as it does not interpret the attributes. It is up to the HPA filter implementation. HPA filter implementation can use aggregate label by figuring out the regions that have that aggregation label. As long as multicloud component provides the aggregation lables for each region (which it needs to do anyway), this is possible. Mechanics discussed are as follows:
- Policy would have Cloud owner and aggregation label information.
- If VDU can be placed, say X number of regions, then there could be X number of policies with each policy having owner and aggregation label.
- HPA filter will choose one of the aggregation label in the policies by matching the aggregation label in the cloud-region.
- If there are no policies with HPA aggregation label or no matching aggregation labels in A&AI, then the HPA capabilities in the policies are used to get the best region set and flavor set in each region.
- It is yet to be discussed whether aggregation label policy support to be implemented in R2 or beyond.
- Policy authoring : Just like distance & latency filters, HPA filters can also be authored manually. That is, even if TOSCA template does not define the HPA capabilities, policies can be added through policy authoring mechanism. If HPA capabilities are specified in TOSCA template for each VDU, then policy is created dyanmically by POLICY ENGINE when the TOSCA template is onboarded. This flexibility is a good thing in that HPA functionality can be tested independent of TOSCA template/SDC-change and POLICY ENGINE changes.