Contributors:
Harish Kajur, Robby Maharajh, William Reehil, CT Paterson, Steven Blimkie
mS Details
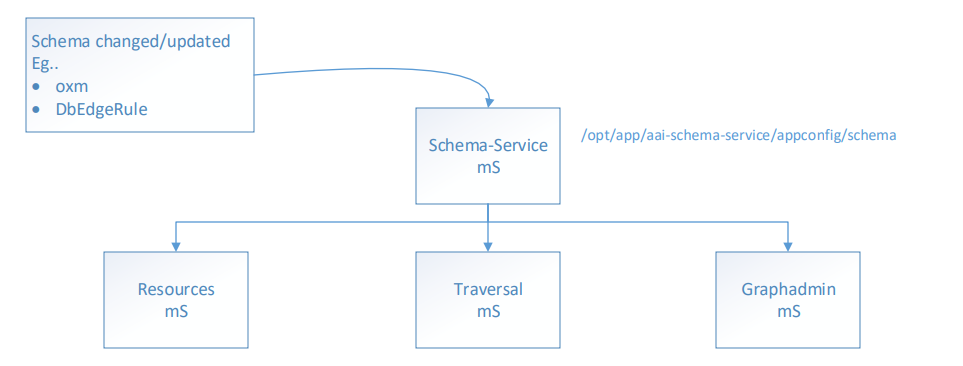
Upon startup, these api s (below**) are used to get the latest schema from Schema-Service
- There are 2 options whether to use the schema from Schema-Service or from local schema directory - at /opt/app/aai-resources (aai-traversal or aai-graphadmin)/appconfig/application.properties - schema.translator.list=schema-service OR schema.translator.list=config · If = schema-service, get latest schema from SS (only when starting up)
- If = config, use existing schema from local directory - /opt/app/aai-resources (aai-traversal or aai-graphadmin)/appconfig/schema (api should be working fine even if SS is down) **** There is no guarantee that schema version at local directory will be the same as in Schema-Service mS or get updated on the fly. A setting schema.translator.list= config should only be used in a very rare situation in case SS can t start up. **Ecomp (AAI-14983)
- /aai/schema-service/v1/nodes?version={version}
- /aai/schema-service/v1/edgerules?version={version}
- /aai/schema-service/v1/versions
- /aai/schema-service/v1/stored-queries
New Installation Requirement
- Schema-Service has to be installed and started (in healthy status) before other mS.
- If there is a new Schema-Service build installed; Resources, Traversal and Graphadmin mS needs to be restarted
- Resources, Traversal and Graphadmin will fail to restart if Schema-Service is not up running (unless schema.translator.list=config
----- Everything Below was during the design/requirements phase of schema service ----------
Overview:
- Currently, changes in schema are delivered via new builds of microservices that consume them
- Tracking and testing changes via new builds takes longer
Dublin Requirements:
- The solution must provide the foundational layer for consuming dynamic schema changes in the future
- AAI schema service must support the ability to centrally persist (build-time) and serve (run-time) schema via REST
- AAI schema service must support the ability to centrally persist (build-time) and serve (run-time) custom queries via REST - removing the custom query definitions from the traversal service and making the schema service responsible for them.
- AAI schema service must support the ability to provide a complete schema as one document even if persisted via multiple files
- AAI schema service must support the ability to provide a list of documents stored
- AAI schema service must support the ability to provide an individual document
- AAI schema service must support the ability to provide associations/grouping between documents (needs more clarity)
- OXM and Edgerules paired by version [v11, v12, v13]
- Grouped by usecase w/ multiple OXM files
- AAI schema service must continue to support clients that consume the schema via XSDs and POJOs as build-time artifacts
- MSO uses this, and would have to update configuration for the location
- Followup item: Check with SEs on who is consuming the XSDs
- Client AAI microservices that are configured to depend on the Schema Service will wait for the AAI Schema Service instance to start
- AAI must support the option to load the schema files in a development mode (loading locally)
- Client AAI microservices that currently depend on aai-common / aai-schema artifact at build time must use the AAI schema service REST API as its source for OXM schema files and edge rules (if configured to do so)
Epic for effort: AAI-1859 - Getting issue details... STATUS
Use cases/open questions:
- Multiple instances of AAI running with entirely separate schemas
- William Reehil - The user would specify which schema it requires when communicating with the schema service regardless of version or instantiation of the framework (implementation details will be worked out)
- Scenario where an attribute is changed interactively by the user - system engineer or dev for testing/proof of concept - and then how to commit that change to the schema service to make it permanent
- William Reehil - For Dublin, schema changes would still go through version control. Future enhancements would include the ability to make changes dynamically at run-time, as long as the changes are non-disruptive.
- Differences between build-time and run-time dependencies - current function, user updates schema file(s) and/or edge rules. This is a run-time interface to a static configuration. Even though it can be set/changed at run-time, for Dublin, the schema/edge rules will remain a build-time dependency for the schema service but is a run-time dependency for the internal AAI microservices that consume the schema service.
- William Reehil - Schema is not targeted to be modified at runtime for Dublin, future enhancements.
- AAI clients that use XSD will consume the schema service artifacts, and will not consume an XSD via REST API
- What happens when we have conflicts - what conflicts can arise and how they detected and remediated
- Auditing on multi-oxm overlap / conflicts
- Multi-oxm to split administrative types from inventory types
- Does the mutli-oxm which allows the same java-type in more than one file make sense?
- Impact on history feature - follow up with William Reehil and Robby Maharajh, invite them to next week's call to discuss
- William Reehil - Only impacts Chameleon & Champ, changing how they retrieve the schema information, they would now retrieve from the schema service. How Champ loosens it's constraints is up for discussion.
- William Reehil - Schema migration changes will be reflected as just changes in the history of the node, there could be special cases here, but we should not allow dynamic changes to the schema that require schema migrations. Note - history design is not finalized since it had been put on hiatus during the design phase.
- Sparky, Resources, Traversal, GraphAdmin, GraphGraph, Champ, Chameleon will use the schema service to get knowledge into the schema and edge rules of the instance.
- Vision: The schema service will allow various ways to get information about the schema and edge rules through its exposed endpoints, allowing for scope control and ease of understanding. Consumers should not be bound to a singular file format or consummation of the entire configuration file. This is increasingly important when speed is essential and the format should be flexible to accommodate its users. For example, say Sparky just needs to know the attributes of the x node, it should not have to load the entire configuration file in XML format to find out that information. Ideally it should just be able to ask the schema service "What are the attributes of the x node in JSON format?" Then taking this a step further we would like to leverage this service to act as the central hub of schema modifications, but this will require in-depth discussions on how to make this work.
Hey William Reehil (it's me Pavel Paroulek) - I think you written exactly what I suspected - that it would be a mistake to start the implementation of schema service In Dublin, the only selling point which was mentioned by Manisha Aggarwal (dynamic changes, model driven services) is not needed and will be in the "future enhacements". Having a webservice for static content (which as you mention would remain "the schema/edge rules will remain a build-time dependency") doesn't make any sense. Respect +1 ![]() . One thing though - I think your technical argument that it's faster to resolve information about the schema through REST than through direct parsing and memory lookup is not correct (but we can discuss it on the meeting).
. One thing though - I think your technical argument that it's faster to resolve information about the schema through REST than through direct parsing and memory lookup is not correct (but we can discuss it on the meeting).
I think we should now concentrate on the real issue which Venkata Harish Kajur raised - the problematic build times, ease of change and AAI common dependency. I agree with Harishs assessment. We can discuss this all on the meeting.
Proposed Design :
- A mS called Schema Service will hold and load all the schema (OXM and edge rules) at start up
- The Schema Service will hold and load the custom query document at start up
- The Schema Service will provide REST endpoints via GETs such as /aai/schema-service/{api-version}. Consumer mS, such as resource, traversal should use the updated ingest library to make REST calls to the Schema Service
- The REST endpoint for providing the schema will support a "format" query parameter which will describe what format it is requested in eg. GET /aai/schema-service/v1/nodes?version={version}&format=OXM
- The REST endpoints such as /aai/schema-service/v1/nodes?version={version} and /aai/schema-service/v1/edgerules?version={version} will provide a complete schema from multiple files
- The REST endpoint such as /aai/schema-service/v1/list will provide the list of documents stored
- The REST endpoint such as /aai/schema-service/v1/nodes?version={version}, /aai/schema-service/v1/edgerules?version={version} and /aai/schema-service/v1/stored-query will provide the individual document
- The REST endpoint will provide the associations between documents via query parameter "version"
- The schema jar will continue to be provided as an artifact for consumers of XSD and POJOs
- HEAT environment and OOM environment will need to be addressed for Requirement #9
Future enhancements:
- AAI should support the ability to consume new schema dynamically, without downtime (eg. when distributed by SDC)
- AAI should support the ability to notify consumers of schema when new updates are available
- AAI should support an interface to validate proposed schema changes
- AAI should support the ability to provide the schema via flexible document formats (OXM, TOSCA etc.)
#1 and #2 need more analysis of use cases and design. #3 seems to align better with the GraphGraph proposal for viewing and interfacing with the schema. Manisha Aggarwal I think it makes sense for all of what was in graphgraph core to be absorbed by Schema Service, when GraphGraph is being worked.
23 Comments
Pavel Paroulek
Good initial requirements (i.e. before formulating functionality or before defining a REST API) should contain the following:
William Reehil
Business goal of the service: make ourselves more scalable by providing ease of access to our schema to any mS requesting it, centralizing the schema, ensuring it is only maintained in a single area, thus making us more dynamic and paving the way for future model driven efforts. We possibly can expand this to allow for subsets of information to be requested as well
Key Stakeholders: Any user of the A&AI framework, (interacting internal mS and possibly external mS)
Solution Constraints: Can't think of any
Pavel Paroulek
To play the devils advocate, when our goal is to centralize the schema, why don't we store it on a shared persistent volume (as a file). Every pod that would need it can mount it. Scaling is also taken care of as mounting volumes scales linear.
The stated goal is also not aligned with the "Dublin requirement" section
William Reehil
Hey Pavel Paroulek the approach you suggested does not align with our future proposed functionality and would require all who need the information to be able to mount a volume. Why would we limit ourselves like that? If I want to make my schema information available to external microservices or front ends, with your proposed solution this becomes difficult. I think the main thing we are trying to achieve here is laying the foundation to build off of in future releases. Even though we don't have all the specifics on how to implement the end solution, there is merit to building the initial iteration.
Pavel Paroulek
Hi William Reehil, you are right and I agree with you that it does not align with the future proposed functionality - because I think that currently there is no need for any dynamic changes (which was the only argument for a web service solution and against seeking alternatives). There is no business need (no use case, no actors, no external clients or consumers, no anything). I don’t consider it a real requirement because no one was able to come up with any shred of evidence in the 3+ hours we already talked about it. Nil, nada, nothing.
I totally see the problem that Venkata Harish Kajur identified with schema changes and presented on the meeting (long build times, big docker images - I am not sure if you saw his presentation) and I want to solve this real problem. Building a web service for solving the problems that Harish outlined with web services is inefficient and should be (imho) considered as last resort. If we would use my solution (which I don’t claim is the the best one - it should be subject to scrutiny, and we should look at alternatives) we could solve the real problem in 1 man-day, if we start building rest services that no one needs the effort balloons to man-months and continual maintenance, unnecessary memory footprint and maybe it will turn to Champ 2.0, which I would like to avoid. I think we both want the same thing - finding the best solution for AAI.
In conclusion - let us work on the real problem and come up with the best solution. If there are additional issues which would warrant a web service then let’s specify them.
CT Paterson
Hey Pavel Paroulek, William Reehil,
Apologies I've likely missed discussion on the proposed Schema Service in the weekly dev meeting - unfortunately it's a slot I can't reliably make.
I agree with Pavel Paroulek that there could be a few ways to approach this, although I do tend to generally favor the proposal for a few reasons...
The main one is that I do have a business requirement for dynamic updates to schema. I'm working with an adopter of AAI and parts (but not the whole) of ONAP. They are pursuing a service model and schema implementation of their own design (the current ONAP model does not suit their needs), and want to be able to deploy updates to the schema on a live system. This obviously comes with a number of caveats and edge cases we wouldn't support on day one, but simple accretion is straightforward. The solution under consideration includes the following elements:
The schema service would provide a foundation for the third bullet (which I've italicized). I believe it's beyond the scope of what Venkata Harish Kajur and his team have proposed for their initial target, although I have indicated to them that it would be my goal to build on their foundation to accomplish our requirements - quite possibly in the Dublin timeframe.
That case aside, I can see other value in decoupling the schema definition from the software:
The notion of storing the schema on a persisted volume (assuming K8S was used for deployment - I'm not sure it is everywhere), or perhaps as some kind of centralized configuration (if it wasn't so gosh-darned large) would be sufficient to cover off the "write once" scenario that I think the first iteration of the Schema Service seeks to cover. So, again, I agree with Pavel Paroulek that a whole new microservice might be overkill for just that use case.
A config-style loading would not move us in the direction of dynamic updates*, though, and I think would need to be replaced when we went to that next step - so I'm moved to head down the service road. The current requirements and proposed solution are a modest start, and I think are concerned with "first, do no harm" to the existing solution, but the direction is correct. I'm encouraging some of my own colleagues looking at dynamic updates to join this effort rather than roll their own solution.
(* Presuming, of course, acceptance of the use case I describe at the top of this letter...if not, we can talk more. )
)
Pavel Paroulek, let me know what you think. It might be useful to further document the requirements that get into the dynamic needs of the system, even if the first iteration doesn't attempt to address them all (for reasons of time and budget).
Pavel Paroulek
Hi CT Paterson, if the early adopter requires dynamic updates on the live system I can’t think of another way how to accommodate this need than through a service. So this seems to be a real requirement after all. I don’t know if the use case is/will be accepted, but I suspect that if one adopter needs this functionality then there will certainly be more. So I agree with you that we should move in this direction to have a good basis to support the use case you mention.
It seems that your comment brings us to square one - figuring out what the use case of the adopter is, what he needs, what are the requirements. We should understand it before designing the service, for example can we really change the schema dynamically as the adopter would need? How does his use case look like? what happens to the dynamic changes, should they be persisted or are they temporary and lost upon redeploys? who changes the schema - a human or a robot? Do we need a gui? How often does it change, how quickly do the changes need to be picked up by the services? what happens when some services picked up the dynamic change and some not (time delay)?
Someone should write down the functional and non-functional requirements - I am not saying we need to understand all the features , I am saying we need to understand the nuts and bolts of what we want/need to accomplish. Someone who has access to the source of the requirements should write down what the use case of the adopter is so it is transparent to the community what we do and why.
Until now everything was nebulous and hypothetical, but I think we finally are getting on track.
CT Paterson
Good day, Pavel Paroulek.
I'm certainly good if any of this material makes its way into the requirements above; Harish Kumar Agarwal, William Reehil - let me know what you think. If it helps, I can take on Pavel Paroulek's questions here:
what happens when some services picked up the dynamic change and some not (time delay)?
I also feel the need to make a clarifying statement about SDC. This might be controversial (and I'm all for a good debate), but I consider AAI loosely coupled from SDC. Right now, in ONAP, models are distributed via SDC - that's all well and good, and my preferred solution. However, I've never been satisfied to hold AAI's capabilities back if a real need was identified and SDC could not move fast enough to support it. Some carriers are adopting ONAP as a whole; most who I've talked to are taking pieces, but not every component. The use case above has challenges for AAI and challenges for SDC - but we haven't used any SDC challenges as a reason not to do something in AAI (though we have used it for reasons of how and when).
I raise that for two reasons; (1) there's any number of things I just mentioned above where someone could look and say "but SDC doesn't do that!" I know - customer wants it, and it's not going to stop me; if SDC gets on board, great; if not, I'll work around it. (2) This is concretely highlighted in some additional annotations we've included in our schema to drive AAI system behavior that today SDC does not support. It's outside of the scope of what a Schema Service (in any form) might be asked to address; its a problem of the transpiler/translator - but I'm happy to get into it another time.
I hope this was helpful.
Cheers.
Pavel Paroulek
Hi CT Paterson thanks for all the information, I am glad you have started shedding light on the schema service.
I think we have to get our story straight, because first it was told that a systems engineer will be doing dynamic changes and we structured the initial requirements accordingly, then the requirements were elaborated and the reasons and goal were formulated in technical non-business term of centralization and loose coupling (which are actually design solutions not requirements) and now a new story is presented - unreleased ecomp components and an adopter (what is the name of the adopter?) need this functionality and require a schema service.
I think whoever is in charge of the requirements should pull all these narratives together and create a coherent story what we want to do and why. We can discuss it further on the dev meeting.
CT Paterson
Thanks, Pavel Paroulek,
I think what we're seeing is a convergence of different stories onto a common solution that can (to varying degrees) address points of those stories. The narrative I supplied is not the use case that Venkata Harish Kajur and William Reehil are pursuing. We have different objectives, but I think we can find common ground for much of it. My thread has been about why I support their approach and have interest in the outcome, because it goes some distance to addressing my needs as well (which I was happy to elucidate).
I don't know that there's one person who we can expect to pull the narratives together to create the story. I rather thought that's what we all were doing.
Cheers.
Pavel Paroulek
Hi CT Paterson,
I don't think the stories converge as issues that the guys identified do not warrant a web service (as you said and I couldn't agree more "... the whole new microservice might be overkill for just that use case..."). The story of the system engineer needing to make dynamic changes was a strange one and never brought up again so I am not sure what to think of that. And finally your story of unreleased ecomp components and the unnamed adopter would suggest a web service is needed.
This is what I expect from good requirements - talking to all the stakeholders and writing down WHO needs WHAT in order to come up with a solution that would accommodate everyones needs (without being an overkill). But until now we are getting REST APIs, design decisions and an urge to commit java code.
If you want to build a single schema web service you need to deal with all the narratives and write down a single spec so you know what to build. The alternative is chaos and different people pulling in different directions a.k.a. the schema service until now.
William Reehil
CT Paterson, I agree with your statements above, I think the one thing we really need to discuss is to what extent we will allow dynamic changes to the model. I would imagine we would want to avoid run-time schema migrations (and that's why I said "Future enhancements would include the ability to make changes dynamically at run-time, as long as the changes are non-disruptive." above, but I think we just need more discussion on this, perhaps there is a way around it). Pavel Paroulek, given just that one use case, I too agree it does not make sense, but there is more to it than just that. The ability to become dynamically model driven from SDC models has been part of our target architecture since I have joined this project, albeit not a primary focus. We have already had similar use cases arise at a higher level for some other areas where we are instantiating our framework internally. Given the issues Venkata Harish Kajur has identified, we believe this will be the best approach to address the immediate need (AT&T's and Amdocs) and be flexible enough to easily evolve in the future. The initial iteration may not accommodate all future stakeholders, but we will be in a much better position to adjust than we are now, having the abstraction layer. As the ECOMP A&AI framework team we have introduced many useful framework enhancements without having formal requirements for immediate use; most recently: bulk apis, response pagination, caching mS, and domain specific language, now they are all being used to some capacity (in internal instances and in the ONAP community). My point is, we need to address immediate concerns while putting our framework in a position for evolution. Becoming model driven through SDC models is on our roadmap.
Pavel Paroulek
Hi William Reehil, thanks, I agree with what you said. I think we are finally getting somewhere. I have 2 points
William Reehil
Hi Pavel Paroulek,
Probably best we discuss this on the call tomorrow, not sure if my intentions are being communicated properly, we certainly want to be transparent. I stand by everything I have stated as truthful. I thought the plans to move towards the SDC model-driven approach were well known in the ONAP community. Might be that hasn't come up on Jimmy's calls in a while. In the stories written in the ONAP JIRA for this schema abstraction layer, we have outlined the ability to configure how the schema is loaded, so the framework implementer can choose how they want to load the schema (and can define their own implementation easily as well).
William Reehil
Pavel Paroulek, also addressing #1, there is no secret (to my knowledge) on why we need the service, other than to position us towards our target architecture and address the issues Venkata Harish Kajur mentioned along with providing the platform for the requirements CT Paterson would like to implement.
Pavel Paroulek
Hi William Reehil, I think I didn’t understand your intentions, probably because there is nothing about it in the requirements and I don’t remember anyone discussing it on the meeting when I asked why do we need a schema service. The focus of the discussions was on providing dynamic changes which I don’t know if anyone could justify and I am again perplexed since we have a (for me) new narrative about importing SDC TOSCA CSAR schemas.
The discussion started going in this direction only after CT explained that there is some unreleased transformation service who’s output would serve as a schema for the service - maybe this is common knowledge for you to the extent that it doesn’t have to be mentioned anywhere or explained but I have my doubts if this is known in the wider community.
Also when you re-read the comments chronologically you just see the struggle to figure out why are we doing what we are doing.
I feel like everyone has his/her version of what the schema service is/should be and it’s really hard to get a straight answer because everyone is on a different page.
William Reehil
Pavel Paroulek, okay I think I see the disconnect, but yes we want to introduce this abstraction layer to ready our framework for dynamic model updates, due to the SDC model → A&AI target architecture. For Dublin, we (AT&T) were not planning to actually work towards the dynamic model updates, as that opens much broader discussions on how to handle various scenarios. What we wanted to address with this schema service was more geared towards laying the foundation to allow us to build on top of it to eventually get to a point where we could have dynamic changes to the schema, while addressing the issues Venkata Harish Kajur(AT&T) identified. CT Paterson (Amdocs) has identified his use cases, which I believe also align with what we are trying to build. I was not aware prior that anything for Dublin would be done as far as dynamic updates, which would then open that topic for discussion. That could take time, and I don't think it should impede on the initial service development. Having an abstraction layer provides a great deal of benefits for the evolution of our framework. Such benefits include schema centralization, decoupling of schema/microservices, ease of use, ease of broad access, ability to modify underlying implementation transparent to the end users, ability to easily format, transform, or retrieve subsets of schema information, among others. It provides us a lot of flexibility on not being bound to a singular static implementation.
Keong Lim
I like all of this discussion, but would like to reiterate points made during the previous AAI Dev call:
If there is already a plan, it would be great to see the plan laid out in this fashion.
If there is not yet a plan, this could be a good way to make the plan.
Keong Lim
I think the changes in https://gerrit.onap.org/r/73997 for AAI-1982 - Getting issue details... STATUS is another important scenario for AAI Schema Service to deal with.
WWASSD (What would AAI Schema Service Do?)
Pavel Paroulek
ROFL @ WWASSD
Keong Lim
Here's another one for WWASSD: Proposal to Change AAI PNF Entity to use PNF-ID as key
and DCAEGEN2-885 - Getting issue details... STATUS
Keong Lim
A schema optimisation: the JIRA case is too brief AAI-1987 - Getting issue details... STATUS but the gerrit comment is descriptive https://gerrit.onap.org/r/#/c/74232/
Keong Lim
WWASSD with Steve Smokowski proposal for new schema in SO-1270 - Getting issue details... STATUS / https://gerrit.onap.org/r/74231 ?