Issues to be resolved
- When should scaling be done?
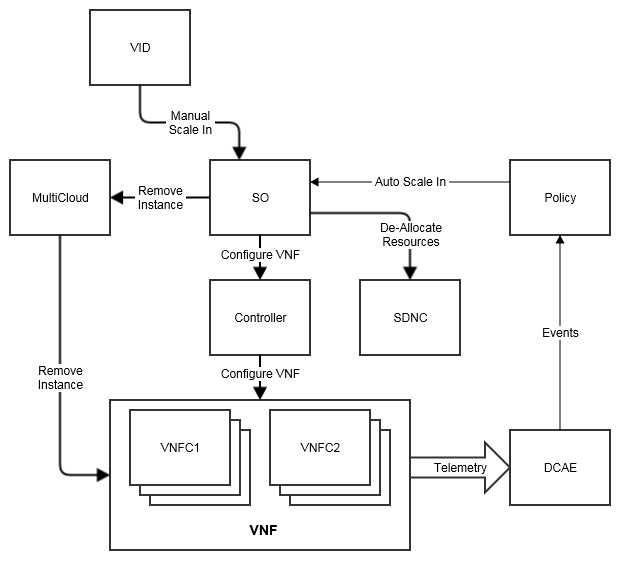
- In Dublin our primary reason for scaling will be focused on adjusting resources to the load. As load increases or decreases, the VNF will scale Out or In as appropriate. This can be done either manually or automatically.
- Other reasons for scaling may include:
- Upgrades
- VM Moves
- Meet with Operations to determine other reasons
- Which instance should be removed?
- How should Policy be involved? (Long term: Policy should query an OOF microservice)
- Last In First Out as a temporary solution? (Dublin: will need to query for all instances and then choose)
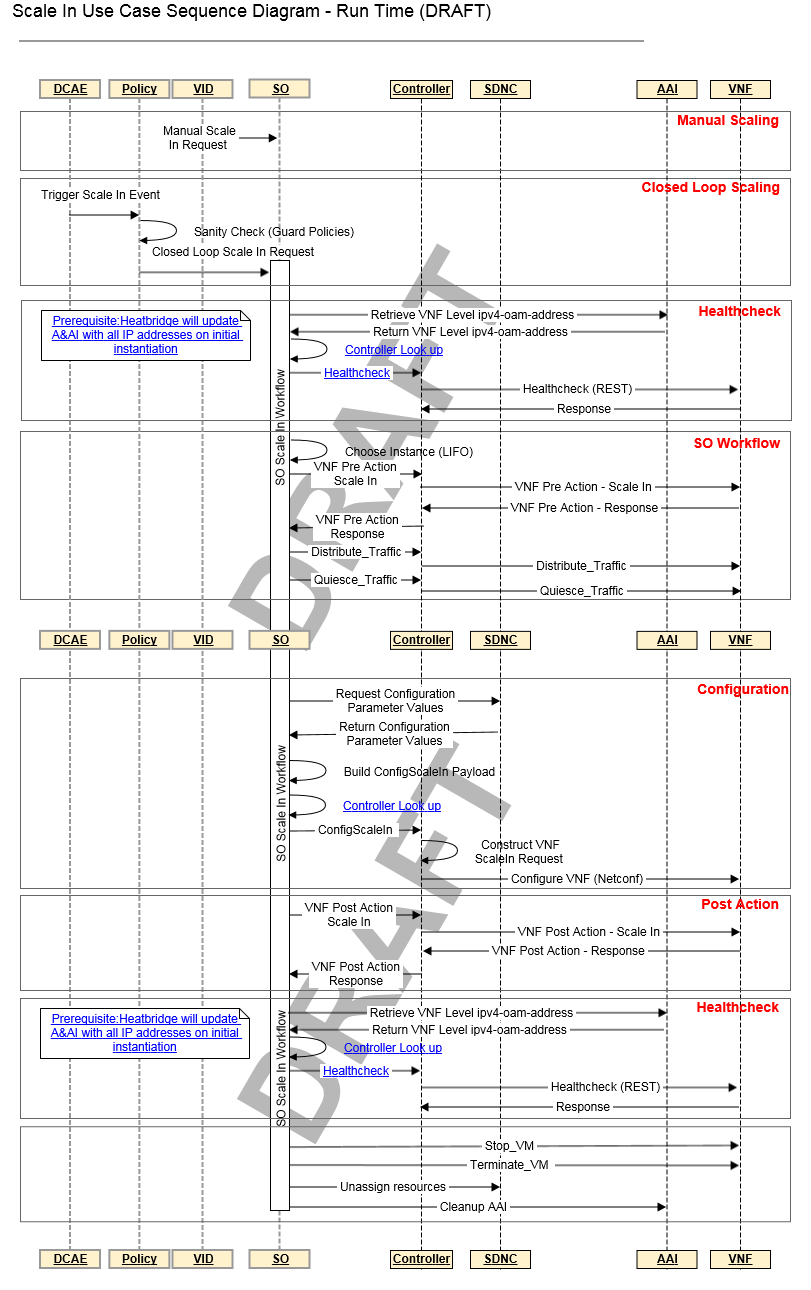
- We need a generic Pre-Action API with a scale in flag to trigger a scale in playbook. This will allow the VNF to do any VNF specific actions prior to a scale in action
We need a generic Pre-Action API with a scale in flag to trigger a scale in playbook. This will allow the VNF to do any VNF specific actions prior to a scale in action
- In onboarding package vendor needs to say whether or not they support a Pre and Post action
- How do we use Distribute_Traffic?
- Distribute_Traffic will move all new traffic
- Will need to make Distribute_Traffic work at the VM/VNFC level
- Quiesce_traffic can be used for returning a response once all traffic is drained from the target instance
- will need to make Quiesce_Traffic work on the VM/VNFC level
- Need to build a ConfigScaleIn action and API for APPC and SDNC
- Will we be able to use CDS for AutoConfiguration?
- How do we determine which controller to use?
- STOP VM before Termination
- Scale In will release all resources. It is not guaranteed that the same resources will be reassigned on the next scale out.
6 Comments
Scott Blandford
To Do Items:
Assumptions:
Lathishbabu Ganesan
In the SO wrokflow, Decide which instance to scale in. We could have a mechanism to identify the least traffic instance to ease the traffic migration.
Scott Blandford
Pamela Dragosh is looking into using Policy to make this comparison and delivering on a flexible policy driven criteria. I am also going to check with the architecture team to see how they would approach this issue. In my mind it is really an optimization issue since you might choose based on traffic, # of stream, lowest CPU, oldest version, etc. If there is no way to easily configure this choice in Dublin then we may want to choose a very simple algorithm (eg. LIFO) in the short term and begin development of a flexible capability for the future.
Lathishbabu Ganesan
Scale in by modes,
Brutal:
When scale in is triggered, it just randomly deletes the instances.
Graceful:
Identifying which instance to be deleted and migrate the traffic from and delete it.
Design a monitoring system to know the traffic at instance level and based on it the decision is made to delete a instance. This is a graceful way of scale in.
Andrew Fenner, @joss.armstrong@ericsson.com
Scott Blandford
I think we definitely want to stick with your graceful mode. We do not want to abandon traffic flows by deleting instance before the traffic has been migrated.
Marco Platania
Scott Blandford, the sequence diagram for scale in use case strictly reflects the scale out use case sequence diagram that is being implemented for Casablanca. It's a good starting point, but let's keep in mind that components may change for Dublin, so we may need to revisit the chart. For example, if CDS will be fully delivered and usable, then we may not need the SO-Controller payload, because the controller would be able to resolve the scale in parameters via data dictionary.