Name of Use Case:
Use Case Authors:
combination of use cases proposed by (in alphabetical order):
AT&T, China Mobile, Ericsson, Metaswitch Network, Orange
Description:
A Mobile Service Provider (SP) plans to deploy VoLTE services based on SDN/NFV. The SP is able to onboard the service via ONAP. Specific sub-use cases are:
- Service onboarding
- Service configuration
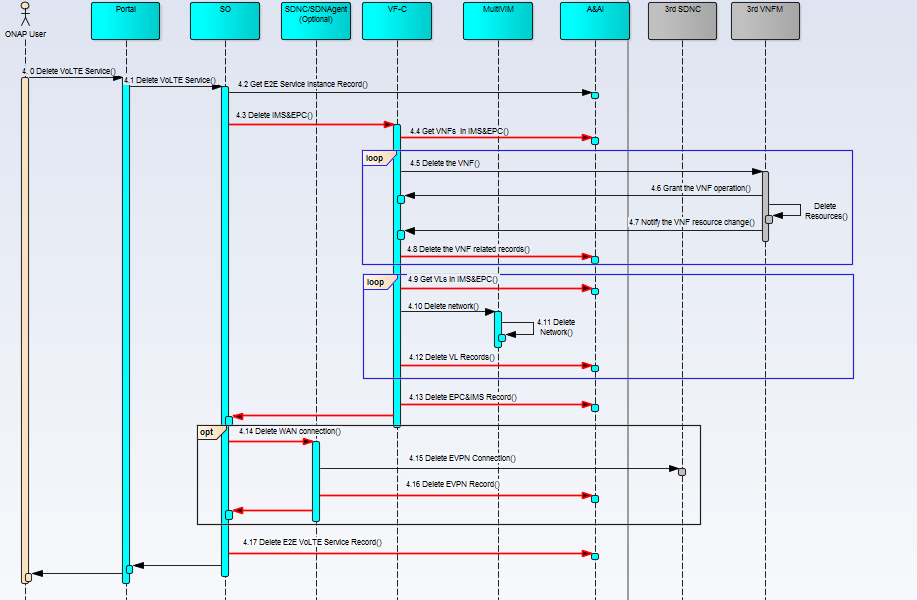
- Service termination
- Auto-scaling based on fault and/or performance
- Fault detection & correlation, and auto-healing
- Data correlation and analytics to support all sub use cases
ONAP will perform those functions in a reliable way. Which includes:
- the reliability, performance and serviceability of the ONAP platform itself
- security of the ONAP platform
- policy driven configuration management using standard APIs or scripting languages like chef/ansible (stretch goal)
- automated configuration audit and change management (stretch goal)
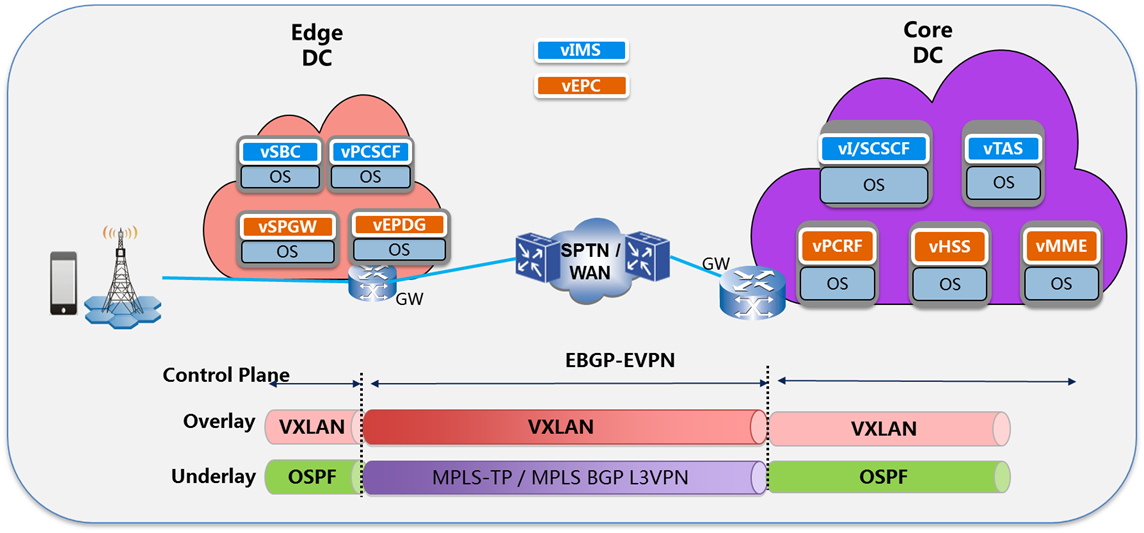
To connect the different Data centers ONAP will also have to interface with legacy systems and physical function to establish VPN connectivity in a brown field deployment.
Users and Benefit:
SPs benefit from VoLTE use case in the following aspects:
- service agility: more easy design of both VNF and network service, VNF onboarding, and agile service deployment.
- resource efficiency: through ONAP platform, the resource can be utilized more efficiently, as the services are deployed and scaled automatically on demand.
- operation automation and intelligence: through ONAP platform, especially integration with DCAE and policy framework, VoLTE VNFs and the service as a whole are expected to be managed with much less human interference and therefore will be more robust and intelligent.
VoLTE users benefit from the network service provided by SPs via ONAP, as their user experience will be improved, especially during the peak period of traffic
VNF:
Utilize vendors VNFs in the ONAP platform.
TIC Location | VNFs | Intended VNF Provider |
Edge | vSBC | Huawei |
vPCSCF | Huawei | |
vSPGW | ZTE/Huawei | |
Core | vPCRF | Huawei |
VI/SCSCF | Huawei | |
vTAS | Huawei | |
VHSS | Huawei | |
vMME | ZTE/Huawei |
Note: The above captures the currently committed VNF providers, we are open to adding more VNF providers.
Note: The committed VNF providers will be responsible for providing support for licensing and technical assistance for VNF interowrking issues, while the core ONAP usecase testing team will be focused on platform validation.
NFVI+VIM:
Utilize vendors NFVI+VIMs in the ONAP platform.
TIC Location | NFVI+VIMs | Intended VIM Provider |
Edge | Titanium Cloud (OpenStack based) | Wind River |
VMware Integrated OpenStack | VMware | |
Core | Titanium Cloud (OpenStack based) | Wind River |
VMware Integrated OpenStack | VMware |
Note: The above captures the currently committed VIM providers, we are open to adding more VIM providers.
Note: The committed VIM providers will be responsible for providing support for licensing and technical assistance for VIM integration issues, while the core ONAP usecase testing team will be focused on platform validation.
Network equipment
Network equipment vendors.
| Network equipment | intended provider |
|---|---|
Bare Metal Host | Huawei, ZTE |
WAN/SPTN Router (2) | Huawei, ZTE |
| DC Gateway | Huawei |
| TOR | Huawei,ZTE |
| Wireless Access Point | Raisecom |
| VoLTE Terminal Devices | Raisecom |
Note: The above captures the currently committed HW providers, we are open to adding more HW providers.
Note: The committed HW providers will be responsible for providing support for licensing and technical assistance for HW integration issues, while the core ONAP usecase testing team will be focused on platform validation.
Topology Diagram:
Work Flows:
Customer ordering
- Design

- Instantiation

- VNF Auto-Scaling/Auto-healing

- Termination
Controll Automation:
Open Loop
- Auto ticket creation based on the policy (stretch goal)
Closed Loop
- Auto-scaling (stretch goal)
When a large-scale event, like concert, contest, is coming, the service traffic may increase continuously, the monitoring data of service may grow higher, or other similar things make the virtual resources located in TIC edge become resource-constrained. ONAP should automatically trigger VNF actions to horizontal scale out to add more virtual resource on data plane to cope with the traffic. On the contrary, when the event is done, which means the traffic goes down, ONAP should trigger VNF actions to scale in to reduce resource.
- Fault detection & correlation, and auto-healing
During the utilization of VoLTE service, faults alarms can be issued at various layers of the system, including hardware, resource and service layers. ONAP should detect these fault alarms and report to the system to do the alarm correlation to identify the root cause of a series of alarms and do the correction actions for auto healing accordingly.
After the fault detected and its root correlated, ONAP should do the auto-healing action as specified by a given policy to make the system back to normal.
Configuration flows (Stretch goal)
- Create (or onboard vendor provided) application configuration Gold standard (files) in Chef/Ansible server
- Create Chef cookbook or Ansible playbook (or onboard vendor provided artifacts) to audit and optionally update configuration on the VNF VM(s)
- Install the Chef client on the VM (Ansible doesn’t requires)
- After every upgrade or once application misconfiguration is detected, trigger auditing with update option to update configuration based on the Gold Standards
- Post-audit update, re-run audit, run healthcheck to verify application is running as expected
- Provide configuration change alert to Operation via control loop dashboard
Platform Requirements:
- Support for commercial VNFs
- Support for commercial S-VNFM/EMS
- Support for Multiple Cloud Infrastructure Platforms or VIMs
- Cross-DC NFV and SDN orchestration
- Telemetry collection for both resource and service layer
- Fault correlation application
- Policy for scaling/healing
Project Impact:
< list all projects that are impacted by this use case and identify any project which would have to be created >
- Modeling
Modeling will need to be added to describe how VNFs are to be instantiated, removed, healed (restart, rebuild), scaled, how metrics related are gathered, how events are received
Modeling will need to be added to describe the connection service (underlay/overlay) between cloud Edge and Core.
- SDC
Add logic to use the new modeling when designing the service, and then distribute the resulting artifacts - SO
Add logic to understand the new artifacts; orchestrate/manage changes according to it - SDN-C/SDN Agent
Add logic to support to provision the underlay and overlay connection service between clouds, including 3rd party commercial SDN controllers. - DCAE
Support statistics collection on the VoLTE case and receipt of events as per the new model - VNF
Support to integrate with S-VNFM/S-EMS to fulfill the NS lifecycle management and configuration.
- VF-C and DCAE
Support the above control loops - SO/SDN-C/SDN Agent/VF-C
Monitor the service to verify the all NSs/VNFs have been executed, and update A&AI. - A&AI
Support the new data model - Policy
Support new policy related to the scaling and healing in VoLTE use case - Multi-VIM
Support multiple VIMs
Priorities:
1 means the highest priority.
| Functional Platform Requirement | Priority | basic/stretch goal default basic goal |
|---|---|---|
| VNF onboarding | 2 | |
| Service Design | 1 | |
| Service Composition | 1 | |
| Network Provisioning | 1 | |
| Deployment automation | 1 | |
| Termination automation | 1 | |
| Policy driven/optimal VNF placement | 3 | stretch |
| Performance monitoring and analysis | 2 | |
| Resource dedication | 3 | stretch |
| Controll Loops | 2 | |
| Capacity based scaling | 3 | stretch |
| Triggered Healthcheck | 2 | |
| Health monitoring and analysis | 2 | |
| Data collection | 2 | |
| Data analysis | 2 | |
| Policy driven scaling | 3 | stretch |
| Policy based healing | 2 | |
| Configuration audit | 3 | stretch |
| Multi Cloud Support | 2 | |
| Framework for integration with OSS/BSS | 3 | stretch |
| Framework for integration with vendor provided VNFM(if needed) | 1 | |
| Framework for integration with external controller | 1 | |
| Non-functional Platform Requirement | ||
| Provide Tools for Vendor Self-Service VNF Certification (VNF SDK) | NA | NA |
| ONAP platform Fault Recovery | NA | NA |
| Security | NA | NA |
| Reliability | NA | NA |
| Dister Recovery | NA | NA |
| ONAP Change Management/Upgrade Control/Automation | NA | NA |
Work Commitment:
< identify who is committing to work on this use case and on which part>
Work Item | ONAP Member Committed to work on VoLTE |
|---|---|
Modeling | CMCC, Huawei, ZTE, BOCO |
SDC | CMCC, ZTE |
SO | CMCC, Huawei, ZTE |
SDN-C/SDN-Agent | CMCC, Huawei, ZTE |
DCAE/Homles/CLAMP | CMCC, ZTE, BOCO, Huawei, Jio |
VF-C | CMCC, HUAWEI, ZTE, BOCO, Nokia, Jio |
A&AI | HUAWEI, ZTE, BOCO |
Policy | ZTE |
Multi-VIM | VMWare, Wind River |
| Portal | CMCC |
Name of Use Case: vEPC
Use cas authors:
Orange
Description:
Extend EPC capabilities with vSGW and vPGW. Demonstrate how to use a hybrid (PNF+VNF) solution using ONAP

Version 0: no automatic legacy configuration. Deployment on a single OpenStack data-center based with no SDNC
Version 1: only configure legacy MME. Deployment based on a single OpenStack data-center based with no SDNC
Version 2: configure the full EPC (legacy+virtualised) functions on 2 OpenStack data-centers using SDNC
VNF should be compliant with APP-C and DCAE using Netong/Yang for configuration and VES or SNMP for event collections
V0
On-boarding/Design phase
The ONAP designer onboards the VNF descriptors, define the Directed Graphs for the 2 VNF and the legacy MME for configuration and defines the service.
The ONAP designer defines a simple policy rule: to scale vPGW on the basis of the number of sessions and configure the MME to take into account the new vPGW
Open questions:
- do we need to describe the PNF in the SDC ?
- how to plug the legacy MME management solution to APP-C ?
Deployment phase
The ONAP-operating deploys the vEPC service.
As a result, one vSGW and one vPGW are deployed using SO and APP-C and updating AAI.
Closed loop
Triggered on a number of sessions, the policy engine executes the rule that triggers the SO to instantiate a new vPGW and will the APP-C to configure both the vPGW and the MME.

Users and benefits:
SPs benefit from vEPCuse case in the following aspects:
- service agility: more easy design of both VNF and network service, VNF onboarding, and agile service deployment.
- resource efficiency: through ONAP platform, the resource can be utilized more efficiently, as the services are deployed and scaled automatically on demand.
- operation automation and intelligence: through ONAP platform, especially integration with DCAE and policy framework, vEPC VNFs and the service as a whole are expected to be managed with much less human interference and therefore will be more robust and intelligent.
vEPC users benefit from the network service provided by SPs via ONAP, as their user experience will be improved, especially during the peak period of traffic
VNF:
VNF vendors to be defined
VNF open-source available: OAI, openEPC, C3PO
29 Comments
Guy Meador
Topic: Use Case expectations as to compliance to Standards: It would be helpful to the community delivering upon this use case to make explicit any success criteria related to conformance to Standards. A few areas that come to mind that would be important from this perspective would be in the VNF and Network Service models in support of on-boarding/service design. This is particularly important given the goal of attracting VNF suppliers to target the platform.
Randy Levensalor
Will service assurance we included in the policy work item? Ensuring that we have acceptable call quality and don't drop calls are two basic, but critical requirements.
Chengli Wang
As what I understand, auto-healing and scaling both can be seen as service assurance actions. Based on these two control loop demo the automatically operation and management ability via ONAP
Aayush Bhatnagar
It will be good to include the Onboarding of the NFVI itself (Compute, Storage, Memory) as part of this use case. As discussed during the meeting, this is in scope and we can discuss the finer details during the break-out sessions.
Regards
Aayush
Reliance Jio
Chengli Wang
Would you mind clarifying what's you mean 'onboarding of the NFVI itself'?
Manoop Talasila
We may need to consider the impact on Portal component to achieve the security, reliability, and performance of the ONAP platform.
Vincent Colas
I think open-loop operations needs access to performance and faults data from VNFs, for troubleshooting purposes. Could we consider for the use case to have the FM/PM data made available to operator? It could be from internal FM/PM ONAP GUI or sending data to external OSS assurance tools.
Chengli Wang
Auto-healing and scaling actions will depend on the FM/PM data collect from NFVI/VNF
Matti Hiltunen
How are the core and edge data centers selected for the service deployment? When the number of the data centers (especially at the edge) becomes large and when there are a number of constraints related to the placement (e.g., latency to the customer, latency/distance between edge and core data centers, available capacity, legal/regulatory constraints, cost, etc), homing of the VNFs becomes a problem that needs automation.
Oleg Berzin
The vMME placement in the Core DC may be questionable from the network design perspective a number of reasons (some are listed below). It may be better to move the vMME function to the Edge DC:
VoLTE calls require QoS both at the RAN/vEPC level (e.g. LTE QCI1) as well as at the IP transport level. The use case should reflect that as VoLTE QoS is usually a required part of the service.
Oleg Berzin
From the vEPC perspective this use case will also require a vDNS VNF to handle the node selection and APN mapping.
Gervais-Martial Ngueko
auto-scaling and auto-healing feature are related/attached to the new Control Loop Component: "CLAMP", that should be introduced in the coming ONAP release. So it might be worth mentioning that Control Loop Component here.
Ranny Haiby
Thank you for including the workflow diagrams.
The diagrams show only sunny-day scenarios. The use case should cover rainy-day scenarios, e.g. when one of the VNFs in the service fails to create due to lack of resources. What is the expected behavior? Should the process stop and all other VNFs be terminated? Should the process just stop and keep the already deployed VNFs? Addressing this in the flow diagrams may make them too complicated, but the project description should describe if rainy-day scenarios are in scope and what is the expected behavior.
Also, what does step 2.12 in the "Deploy" flow mean? What kind of grant action is performed there? Is that the NFVO resource grant to the VNFM as described by ETSI-NFV? If so, shouldn't the VF-C consult with the Service Orchestrator before granting?
Chengli Wang
I agree with you that functional project should consider rainy-day scenarios.
2.12 Deploy means instantiate the service
Gil Hellmann
There is a clear list of what VNFs and VNFs vendors are proposed to be used for this use case but I can't see any reference to what NFVI HW, and NFVI SW+VIM is proposed for this use case. After all the VNFs and NFVO will need to run on an infrastructure.
Brian Freeman
In the INSTANTIATION flow, the API call from SO to MultiVIM to instantiate the VNF isn't shown/being used. It looks like MultiVIM isnt used at all for the VNF on instantiation, only setup of the Virtual Links. I think VM instantiation is only through the 3rd party VNFM but its not clear. I think for Instantiation you should show the openstack heat engine and the NOVA/NEUTRON calls that will help highlight the assumptions on what cloud is being used and the underlay/overlay assumptions inside that cloud if they are pertinent to ONAP.
danny lin
To add on to Brain's point, for INSTANTIATION, SO would go through VNF-C which makes sense. But for actual VNF creation, whether it goes through VNF-C, or through 3rd party VNFM, eventually, it should come to MultiVIM, which will support VM lifecyle management such as VM instantiation, as proposed in the current MultiVIM project scope.
Oliver Spatscheck
As Lingli has been doing a create job putting this use case together I think it would be beneficial to schedule a review where we go through the flows together. I think that's the fastest way to resolve those questions. Not sure if that's something we want to do in Beijing next week or on the phone before.
Gil Hellmann
This will be a good idea if possible.
Kang Xi
Agree. It'll be good if we can discuss over the phone before the F2F.
Lingli Deng
Happy to host a discussion if needed during the F2F. Not sure if we could do it before the F2F, as we expect people to be starting travelling at the begining of next week. The call flow charts are very high level for illustrative purposes. We will expect the involved projects to give us specific answers on how the actual implementation would be.
danny lin
+1.
Alla Goldner
As we already have Use case subcommittee established, if needed, we will have a Use cases (vCPE and VoLTE) discussion as a part of this subcommittee work during f2f meeting next week.
Lingli Deng
Hi Alla, we have suggested to allocate a slot for usecase in F2F meeting in the Tursday morning.
Alla Goldner
Yes, Lingli, I noticed that.
Brian Freeman
In the spirit of helping add more detail I used the Etherplant tool from Eric@Orange to create flows for onboard, instantiate and closedloop that hopefully will add value to the discussion. Sorry its such a long post but we dont have a common place to run this right now except a VM I put up on Azure to test the tool (which I like )
Brian
@startuml
title VOLTE Onboarding
ONAP_User -> SDC : VOLTE_Edge_VNF(vSBC,vPCSCF,vEPGW,vEPDG) onboarding (TOSCA+image)
ONAP_User -> SDC : VOLTE_Core_VNF(vI/SCSC,vTAS,vPCRF,vJHSS,vMME) onboarding (TOSCA+image)
ONAP_User -> SDC : vVOLTE_Edge service description
ONAP_User -> SDC : vVOLTE_Edge distribution
ONAP_User -> SDC : vVOLTE_Core service description
ONAP_User -> SDC : vVOLTE_Core distribution
|||
ONAP_User -> SDC : vIMS-CW (vI-CSCF,vS-CSCF,vBGCF,vP-CSCF,vHSS,vDNS) onboarding (HOT+image)
ONAP_User -> SDC : vIMS-CW service description
ONAP_User -> SDC : vIMS-CW distribution
|||
SDC -> SO : artifact distribution
SDN -> AAI : artifact distrubtion
SDC -> APPC : artifact distrubtion
note left: DCAE Telemetry ?
note right: VNFM is not part of ONAP so no distribtion
ONAP_User -> APPC : DG creation for vIMS-CW configuration
ONAP_User -> Policy: scaling rule for vIMS-CW
ONAP_User -> Policy: scaling rule for vVOLTE (Edge and Core)
note right: need to determine which VOLTE elements to scale for CI tests
@enduml
@startuml
title VOLTE Instantiation
ONAP_User -> VID : vIMS-CW deployment
VID -> SO : vIMS-CW instantiation
SO -> AAI : inventory update
SO -> MULTI_VIM : vIMS-CW Heat template
MULTI_VIM -> OS_Heat : vIMS-CW instantiation
OS_Heat -> KVM : vIMS-CW instantiation
SO -> APPC : vIMS-CW Configuration using DG
APPC -> vIMS_CW : vIMS-CW configuration
|||
ONAP_User -> VID : vVOLTE_Core deployment
VID -> SO : vVOLTE_Core instantiation
SO -> AAI : inventory update
SO -> VNFM1 : vVOLTE_Core TOSCA template
VNFM1 -> KVM : vVOLTE_Core instantiation
VNFM1 -> vVOLTE_Core: vVOLTE_Core configuration
|||
ONAP_User -> VID : vVOLTE_Edge deployment
VID -> SO : vVOLTE_Edge instantiation
SO -> AAI : inventory update
SO -> VNFM1 : vVOLTE_Edge TOSCA template
note right: Are there multiple VNFM's for vIMS vs vEPC
VNFM1 -> KVM : vVOLTE_Edge instantiation
VNFM1 -> vVOLTE_Edge: vVOLTE_Edge configuration
@enduml
@startuml
title VOLTE Closed Loop
participant vIMS_CW
participant VOLTE_Edge
vIMS_CW -> DCAE : Number of sessions
DCAE -> Policy : Threshold crossing event
Policy -> APPC : scale vIMS-CW
note right: this makes ONAP consistent since \nAPPC has main interface \nto AAI for L4-L7 VNFs
APPC -> SO : instantiat new PGW with scaling template
SO -> MULTI_VIM : instantiate new PGW
MULTI_VIM -> OS_Heat : instantiate new PGW
OS_Heat -> KVM : vPGW instantiation
SO -> APPC : configure vIMS-CW
APPC -> vIMS_CW : configure
|||
VOLTE_Edge -> DCAE : PGW Number of session
DCAE -> Policy : Threshold crossing event
Policy -> VF_C : scale VOLTE_Edge
VF_C -> VNFM1 : scale PGW
VNFM1 -> OS : instantiate new PGW
OS -> KVM : instantiate new PGW
VNFM1 -> VOLTE_Edge : configure new PGW
@enduml
Gil Bullard
I apologize in advance for the length of this post. I hope it adds clarity that is worth the space consumed. After looking more carefully at the VoLTE use case I thought I would provide some thoughts on how we would do this with the seed code AT&T has provided into ONAP. This is intended to provide a more detailed “Instantiate” sequence diagram view that builds on Brian’s sequence diagrams, and which illustrates an option to organize our SO internal structure, leveraging seed code that AT&T has provided into ONAP. We will be supporting the approach described below as an option in SO since we have much of this already implemented, but others may want to use the same approach.
Gil
Here is a set high level summary points to introduce the sequence diagrams:
Example A: Model and sequence diagrams whereby VoLTE is modeled as a Service:
The following sequence diagram illustrates SO behavior driven from a VoLTE service instantiation request, assuming TOSCA modeling example A:
Example B: Model and sequence diagrams whereby vEPC_Edge, vEPC_Core, vIMS_Edge, and vIMS_Core are each modeled as separate independently deployable Services:
The following sequence diagram illustrates SO behavior driven from a vIMS service instantiation request, assuming TOSCA modeling example B:
The following sequence diagram illustrates SO behavior driven from a vEPC service instantiation request, assuming TOSCA modeling example B:
jin xin
Hi Gil:
Thank you for your presentation.
But the pictures of the sequence diagram are fuzzy(Download picture is also misty ).
Could you share the original slides for us?
Thank you
Gil Bullard
Sorry for the fuzziness of the diagrams. Here is a PDF of the original slide set, which will hopefully render better.
Gil Bullard