The following process are copied from Proposed ONAP Release Process Updates for Information and Data Modeling
Only modeling subcommittee related process are listed below:
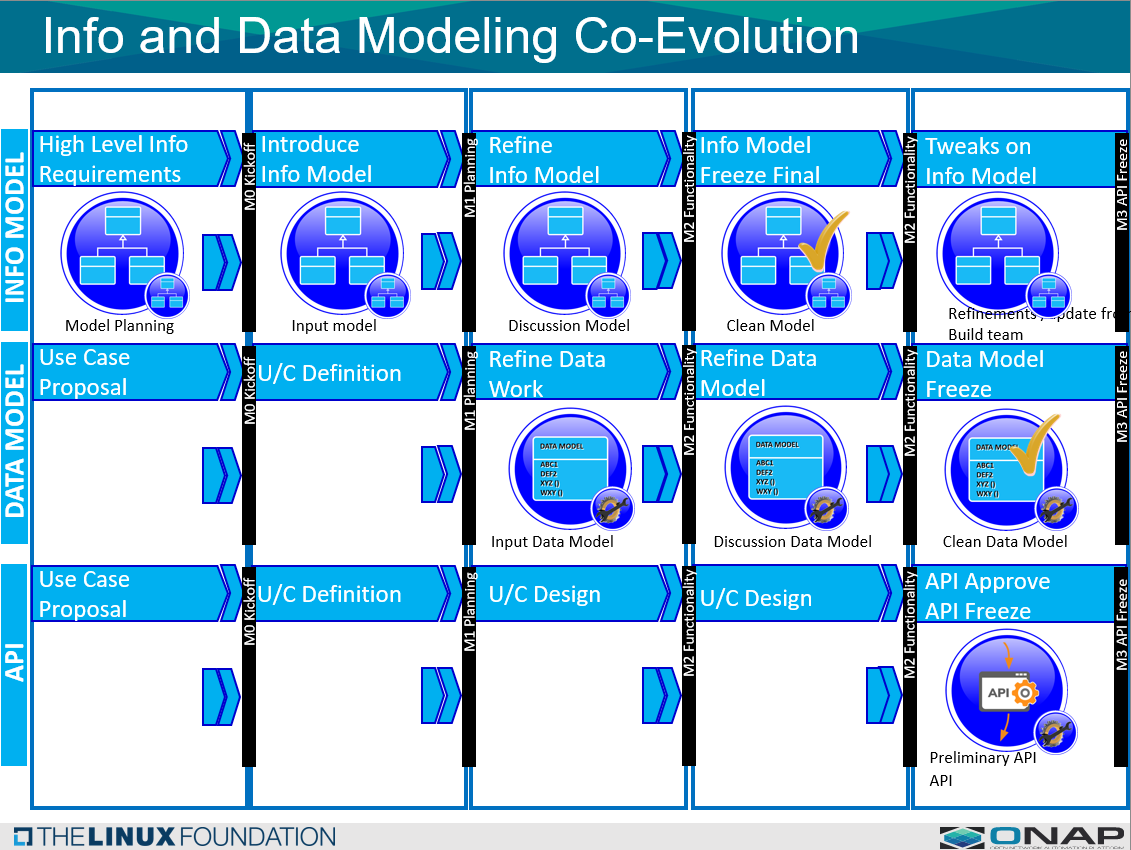
M0 (Gather info and input high level requirements)
- Modeling team - At MO the Modeling S/C does MODEL PLANNING. The planning develops into “High Level Info-model Requirements”. These High level info-model requirements fall into 3 categories:
- #1: NEW USE CASES - items from the expected Requirements/Use Cases in the release (Scope of modeling, continuing, introducing, standards updates). The Use Case Teams should engage the modeling team to propose new requirements into their release planning page. An example of the Modeling S/C planning page for R7 is here: ONAP R7 Modeling High Level Requirements
- #2: REFINING EXISTING MODEL - Refining Existing info-model that has not made it to the information model. Previously designs that need to be added into information model.
- #3: FORWARD LOOKING WORK (FLW) - Modeling future forward looking requirements.
M1 (deadline for high level requirements )
- Modeling team The info-model plan is established by the modeling team which summarizes the modeling requirements for a release. The model planning follows a template that is worked by the modeling team. The release platform Information model updates begin. An example template for R7 (Guilin) can be seen at this Wiki: ONAP R7 Modeling High Level Requirements #1: USE CASE TEAM SYNC - The Use Case teams need to engage the Modeling Sub-committee to make the team aware of potential model impacts arising from their use cases. The modeling team should also become aware of those at a high-level what impacts a use case might have to the release information model. The use cases also need to get into the ONAP Modeling High-level requirements planning page.
M2. (Model Freeze for IM) == follow model subcommitee procedure for freeze (final call and polling)
- MODELING SUBCOMMITTEE -
- For the RELEASE Information Model these are the activities that the Modeling sub-committee is engaged in leading up to M2.
- RELEASE INFORMATION MODEL (Starting Point) - The release starts with a clean release information model from the PREVIOUS release (with all of its attendant contributions). Then new contributions of the current release are considered (see below the process for handling each specific contribution). Potentially a snapshot of the papyrus model and posted into the current release. The RST documentation that only contains things in the current release or everything that is approved.
- TERMS & CONCEPTS -
- IISOMI STATES - The concept of IISOMI states describes the state of individual classes, attributes, and associations/relationships. IISOMI states are noted within the elements of the contribution. For example, a particular parameter might be in the experimental state while another class might be tagged as in the preliminary state. These preliminary and experimental are states that are mutually exclusive so you can't have a class/attributes with two different IISOMI states simultaneously. During the discussion phase, the elements of the contribution should be out of experimental state. The exception is that there is a state of reference that can exist with other states. Some elements within the contribution could have different IISOMI states. The webpage for the IISOMI states can be found at: Informal Inter-SDO Open Model Initiative (IISOMI)
- DELAYED ELEMENTS OF THE RELEASE INFO-MODEL - This may happen that are out of the control the modeling S/C. Use Cases get delayed, or a discussion can't wrap up. So, there could be a corner case where, for example, one or more things (parameters/classes) in a contribution can't make the current release (it stay experimental), what would happen to the overall contribution or release information model (is it allowed to go clean). This would not stop the other parts of the contribution or the release information model from going to a clean state. #@# Example, Dynamic parameters in the common sub-model, generates the whole model then manually edited down to the DP. if things are marked experimental it will show experimental. Keep of Track (experimental?) communicate? reviews?
- INFORMATION MODEL FREEZE - The aggregate / release information model for the release is approved by association with the fragment/ component reviews. Each of the fragment (contributions) are individually approved, thus there is not a "re-approval" or approval of the entire aggregate (release) information model. Editorial clean-up such as misalignments, typos, or sections that were not put in proposal, fixing the template for GenDoc.
- RELEASE INFO MODEL DECLARED CLEAN - After component reviews have concluded and release info model freeze by the modeling S/C the info model is called the "clean model" in this phase. At this point, the Use Case teams that are developing the Data Model can be pretty certain that the information model will be usable as shown. The diagrams and model wiki pages will indicate that this is a clean model. Put into the information model for that release. Unfinished contributions are postponed or discussed further.
- DISCUSSION OF CONTRIBUTIONS - Each contribution discussed according to following process. This is where refining of each of the contribution models occurs by the Modeling Sub-committee (S/C). The release information model is not separately tracked, composed, updated, or released in this period of time. But, rather, each individual contribution has its own Wiki. Thus, for each contribution:
- CONSIDER CONTRIBUTION - START: Input Contribution (verb Consider) END: Contribution in Discussion State
- An individual model contribution is a model that will eventually be a part of the total release information model. It is generally a self-contained model which depicts a particular capability or function of the system. This contribution starts as a "input contribution" and undergoes consideration by the modeling sub-committee. Consideration means that the modeling S/C is entertains & assesses if the input contribution should be accepted into the current (or a future release) by weighing the contribution against its relevance and the available resources (modelers) in the release. If the team thinks that the contribution is not ready for the current release that contribution will be put into a lower-priority and worked if there are no other contributions to be considered as they would take higher priority. Thus, the contribution would not necessarily be rejected, but would get attention as time allows.
- REVIEW & REFINE CONTRIBUTION - START: Contribution in Discussion State (verb Reviewing & Refine) END: Contribution in Discussion state
- The contribution undergoes reviewing & refining during the discussion state. Reviewing & refining means that the modeling S/C is discussing the modeling, and updating the contribution based on feedback and comments from the modeling team. Each contribution can be reviewed and refined independently and concurrently with other contributions. Things in the discussion state are classes, attributes and relationships are tagged as IISOMI experimental.
- FINAL CALL FOR COMMENTS & INITIATE POLLING - START: Contribution in Discussion State (verb Approving/Poll) END: Contribution in Discussion state
- (a) FINAL PRESENTATION - When the contribution has gotten to a point where the team feels that it can start to undergo the approval process, the contribution is brought one final time the modeling S/C for discussion and socialization.
- (b) FINAL CALL FOR COMMENTS - After that, a final call for comments is issued by a sub-team lead to the modeling team whereby final thoughts & input can be given. This final call for comments signals that the discussion is wrapping up for this contribution and will soon go to a poll.
- (c) INITIATING POLL - After final call and no further outstanding comments exist, the contribution is brought to a poll by a sub-committee chair. A poll is created whereby modeling S/C members can give the contribution a vote of "yes" or "no".
- APPROVING CONTRIBUTION - START: Contribution in Discussion State Post-Poll (verb Approving) Contribution in Clean State
- After the poll has concluded, the contribution has finished the approval process. The contribution is now considered to be in the clean state. The items that are in the IISOMI experimental state get promoted to a preliminary state. A gendoc is generated and put on the wiki page. The gendoc would be translated and published on the readthedocs site.
- STEREOTYPE CHECK - The entities in the model has an experimental stereotype (down to the attribute level) when they are a proposal, when approved/clean, all of the entities in that proposal bear change from experimental to preliminary. Stereotypes can be on classes, attributes, data types and relationships. It is an ISOMII add into the model, at a high-level in the model things get stereotypes. E.g. when we approved the first VES model, which has many entities and many attributes; to update all of those from experimental to preliminary was tough. A stereotype is a status marker. Preliminary is approved for development.
- CONSIDER CONTRIBUTION - START: Input Contribution (verb Consider) END: Contribution in Discussion State
M3 ( IM final and DM model freeze) DM need to be viewed jointed by SDC and modeling subcommittee
- M3 MODELING SUBCOMMITTEE ACTIVITIES -
- REFINEMENTS TO THE RELEASE INFO MODEL - The Release Information Model is clean at M3. It is considered "base-lined" and "final", hence it is marked clean. Though, updates can still happen to the release information model and the model contributions therein. This means that certain elements within the model(s) could go to back to an experimental state. Note that only certain elements (e.g. attributes, ranges) are likely to go to the experimental state NOT the entire contribution. More often though, new additions could be added to a contribution model. In general, there would likely be just minor tweaks on the model. So when a contribution is clean it has to be at least preliminary. A contribution cannot be clean and experimental. Clean has a relationship to the IISOMI states. For an entity to be clean it must be either preliminary or mature (see the IISOMI state diagram link).
- IISOMI STATES - A link to the IISOMI state diagram can be found here: Stereotypes
- NEW ADDITIONS - A contribution model could be clean, but things added afterwards and those elements would come in as experimental.
- STILL IN PROGRESS ITEMS IN RELEASE INFO MODEL - It is possible that as the modeling team enters the M3 milestone that there are still some things in progress, that are expected to be in the current release. They might still be marked experimental even though the release information model is clean. Thus, to open item are continue to be work; and it is expected it would not affect software if code were already associated to it.
- ITEMS IN DISCUSSION - e.g. when root contribution was done, with root party is an example as it was not agreed to, we made the decision to leave that experimental until a future date. There were aspects agreed, and other things left experimental to pursue in the future. The main contribution was split. These parts everyone agreed with and these part left experimental which would be taken up in a future contribution and re-discussed. This would likely occur at M2, and they might be discussed at M3. There was a conscious decision and agreement by the modeling team that the parts of the model still open would be pushed to the next release. So only theoretical discussion would happen at this point of how to proceed in the future release.
- FUTURE WORK - Things originally planned to be in a release could potentially transform into future work items. Some modeling work could be pushed to the next release if need be, if it is decided that it could not be completed in the current release.
- FUTURE WORK - Future work is typically identified as such at the start of a release at M0 in the release modeling planning page. Future Work can still proceed. For example, in R6 the geo-location modeling work is not tied to any active development yet. The location work is a good example of work that was worked in ADVANCE of when it is expected to be used (Future Work). It is also possible that some of the future work is building upon a foundation of work that had already been started (or was looked at) or implemented in a prior release.
- DEFER WORK - It might be decided the the future work could be deferred to the next release. On the current modeling high level requirements page to indicate that a particular future work has been deferred to a future release. In order not to lose the activity, it would be expected that it would be rolled into the next release's Modeling High-Level Requirements.
- CONTINUE WORK - Future Model work may continue to proceed in the current release..
- DOCUMENTATION AFTER IMPLEMENTATION IN PRIOR RELEASE WORK - This type of work is the model is catching up to already implemented software. It has already been identified as something that would be worked on for that release at M0. It is expected that it wouldn't immediately impact the current software. However, it may be extended eventually to incorporate new work. The way to proceed with this category of work is handled the same way as the future work (i.e. Defer or to Continue the work) given modeling improvement recommendations on how better to model a given concept.
- M3 CHECKLIST - The M3 check list modeling updates discussion is used by the modeling sub-committee. It is used as a vehicle to engage the Use Case (project teams) and reconcile the Use Case Teams with the modeling S/C team's work. See also the Use Case Team Engagement (section below). The Check list can be found here: Proposed M3 Checklist modeling updates discussion
- REFINEMENTS TO THE RELEASE INFO MODEL - The Release Information Model is clean at M3. It is considered "base-lined" and "final", hence it is marked clean. Though, updates can still happen to the release information model and the model contributions therein. This means that certain elements within the model(s) could go to back to an experimental state. Note that only certain elements (e.g. attributes, ranges) are likely to go to the experimental state NOT the entire contribution. More often though, new additions could be added to a contribution model. In general, there would likely be just minor tweaks on the model. So when a contribution is clean it has to be at least preliminary. A contribution cannot be clean and experimental. Clean has a relationship to the IISOMI states. For an entity to be clean it must be either preliminary or mature (see the IISOMI state diagram link).
- M3 MODELING SUBCOMMITTEE ACTIVITIES -
Observations
Establishes and Evolves a Common Model
Project (Component) Team Involvement in Modeling Solution
Governance of Common Model and Corresponding Component Models
- Update possible in M3 and M4 (bug fixes) per exception process
Artifacts
Information Model Artifact Contains
Classes
Relationships with Multiplicity
Important Attributes with Multiplicity
Definitions
Data Types
Feed to Data Dictionary
Tooling - Papyrus with GitHub
Component Data Model Artifacts (Implementation Specific)
Component Data Model
Contains objects, attributes, & relationships (more detail than information model)
Mapping to Information Model
Feed to Data Dictionary?
API Artifacts
API Model
Mapping to Information Model
New Roles – Model Governance
Information Model
Internal Committers
Internal Approvers
Impacted Project (Component) Approvers
Impacted API Approvers
Architecture Group Approvers
Component Data Models
Internal Committers
Modeling Team Approvers
Architecture Approvers
Impacted API Approvers
API Definitions
Modeling Team Approvers
Impacted Project (Component) Approvers
Architecture Approvers
Benefits
Establishment and Evolution of a Common Model (Model Consistency)
Continue Move Toward a Model Driven Design
Improve Data Quality