Introduction
This document explains how to run the ONAP demos on Azure using the Beijing release of ONAP.
The Beijing release had certain limitations due to which fixes/workarounds have been provided to execute the demos. The document contains the details of the fixes/workarounds and the steps to deploy them.
Current Limitations of Beijing Release and Workarounds
| S.No | Component | Issue detail | Current Status | Further Actions |
|---|---|---|---|---|
| 1 | SO | Custom workflow to call Multivim adapter | A downstream image of SO is placed on github which contains the custom workflow BPMN along with the Multivim adapter. | A base version of code is pushed to gerrit that supports SO-Multicloud interaction. But, this won't support Multpart data(CSAR artifacts to pass to Plugin). This need to be upstreamed. |
| 2 | MutliCloud plugin | Current azure plugin on ONAP gerrit does not support vFW and vDNS use-cases | Using the downstream image from github and developed a custom chart in OOM (downstream) to deploy as part of multicloud component set. | Need to upstream the azure-plugin code to support vFW and vDNS use-cases. |
High level Solution Architecture
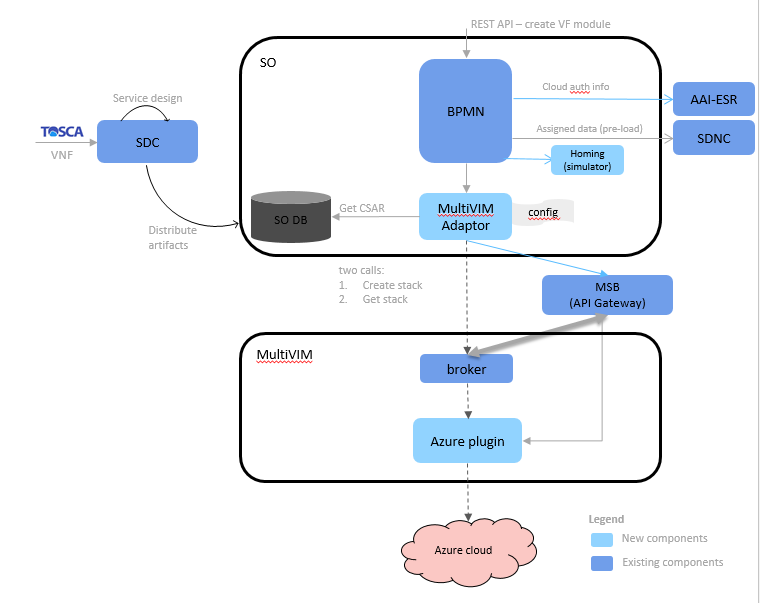
The High level solution architecture can be found here
Deploying ONAP on Azure using Beijing Release
ONAP needs to be deployed with the dockers containing the workarounds provided for the limitations in the Beijing release.
The OOM deployment values chart have also been modified to deploy the dockers with the fixes.
The detailed list of changes is given below:
| S.No | Project Name | Docker Image (Pull from dockerhub repo) | Remarks |
|---|---|---|---|
| 1 | OOM | NA | Contains the latest values.yaml files which point to downstream images of: That include:
|
| 2 | SO | elhaydox/mso:1.2.2_azure-1.1.0 | Contains the VFModule fix along with the newly developed BPMN and Multi VIM adapter |
| 3 | multicloud-azure | elhaydox/multicloud-azure | Aria plugin to interface with Azure and instantiate VNFs |
Deploying ONAP on Azure
Creation of Kubernetes cluster on Azure
Login to azure
az login --service-principal -u <client_id> -p <client_secret> --tenant <tenant_id/document_id>
Create a resource group
az group create --name <resource_group_name> --location <location_name>
Get the deployment templates from ONAP gerrit
git clone -o gerrit https://gerrit.onap.org/r/integration cd integration/deployment/Azure_ARM_Template
- Change arm_cluster_deploy_parameters.json file data (if required)
Run the deployment template
az group deployment create --resource-group deploy_onap --template-file arm_cluster_deploy_beijing.json --parameters @arm_cluster_deploy_parameters.json
The deployment process will take around 30 minutes to complete. You will have a cluster with 12 VMs being created on Azure(as per the parameters). The VM name with the post-index: "0" will run Rancher server. And the remaining VMs form a Kubernetes cluster.
Deploying ONAP
SSH to the VM using root user where rancher server is installed.(VM with postindex:"0" as mentioned before)
Helm upgrade
When you login to Rancher server VM for the first time, Run: "helm ls" to make sure the client and server are compatible. If it gives error: "Error: incompatible versions client[v2.9.1] server[v2.8.2]", then
Execute: helm init --upgrade
Download the OOM repo from github (because of the downstream images)
Get install script on Azure VMgit clone -b beijing --single-branch https://github.com/onapdemo/oom.git
Execute the below commands in sequence to install ONAP
Get install script on Azure VMcd oom/kubernetes make all # This will create and store the helm charts in local repo. helm install local/onap --name dev --namespace onap
Due to network glitches on public cloud, the installation sometimes fail with error: "Error: release dev failed: client: etcd member http://etcd.kubernetes.rancher.internal:2379 has no leader". If one faces this during deployment, we need to re-install ONAP. For that: helm del --purge onap rm -rf /dockerdata-nfs/* #wait for few minuteshelm install local/onap --name dev --namespace onap
Running ONAP use-cases
Refer to the below pages to run the ONAP use-cases
Building the Source Code with fixes
If you want to take a look at the fixes and create the dockers for individual components, the source code for the fixes is available Source Code access
28 Comments
Alka Choudhary
This is the recording wherein Beijing deployment on Azure using OOM is show-cased. ARM template is used for this deployment.
Brian Freeman
Is there a matching page with instructions for Casablanca ? I tried to install Casablanca and many components installed but ran into the Azure CNI networking issue with No MAC Address Found. wasnt able to work around it. Not sure if the default install I was using installed a version of k8 that was invalute - it seemed to be the 1.8 client with the 1.10+ server.
Brian Freeman
Most of ONAP Casablance installed but it seems like timeouts are occurring inside the K8 cluster (I use a 9 node K8 cluster)
Using Casablanca install:
helm deploy dev local/onap -f /root/integration-override.yaml --namespace onap
...
Release "dev-sdnc" does not exist. Installing it now.
Error: release dev-sdnc failed: Timeout: request did not complete within allowed duration
Release "dev-so" does not exist. Installing it now.
Error: release dev-so failed: Internal error occurred: failed to allocate a serviceIP: client: etcd cluster is unava ilable or misconfigured; error #0: client: etcd member http://etcd.kubernetes.rancher.internal:2379 has no leader
Did you run into this ?
Sudhakar Reddy
Hi Brian,
Yes we did run into this issue.I also mentioned the same in above note. etcd in kubernetes runs only in cluster mode and is very sensitive to the networking between the nodes.
In case of such failure, I usually delete the release and then re-deploy again.
In the above case:
helm del --purge dev-so
helm insall local/so --name dev-so --namespace onap
Brian Freeman
In looking at the performance issues I am wondering if the dockerdata-nfs setup with General Purpose Storage V1 is a problem. Have you tried Premium storage for the rancher /dockerdata-nfs ?
Is there a simple change to the Azure template for that ?
Also - wouild it help k8 if we increased the liveness probes for the applications as well from the current 10-30 seconds to more like 60 - 120 seconds ?
Brian Freeman
I'm also wondering if the problem might be the storage class for /var/lib/docker since its HDD based.
Could we configure /var/lib/docker to be on SSD for both rancher and the k8 hosts ?
Brian Freeman
Trying Standard DS4 v2 instead of Standard D4 v2 - wait % is much better for base kubernetes install which is a good sign
Brian Freeman
Casablanca OOM install puts etcd on separate VMs (m1.large) can you update the Azure Templates in gerrit for this configuration as well
Per Gary this is running etd on a separate Resiliency Plane (etcd=true on those three VMs/hosts)
Brian Freeman
A few suggestions.
Brian Freeman
I noticed than when VM's rebooted the hostname presented to k8/rancher didnt match the original registration. Seeems like adding a /etc/host entry fixed the problem
10.0.0.210 node10
for example
ArunKumar Amarnath
Sudhakar Reddy , I followed the instructions & the infra got created in Azure, But when I tried giving in "helm ls"/ "helm init --upgrade" its throwing out an error saying "Error: serializer for text/html doesn't exist". Any help is appreciated.
Yashvanth Honnegowda
Please let me know what is the password for root user for Azure VM
Sergey Kolpakov
Look like I have the same question, please advice where and how I can get pwd for root user for created VMs in Azure
Brian Freeman
You must use the ssh key as onap_user to access the VMs in Azure. See deployment.txt for the path to the dynamically created key.
--------NFS ACCESS--------
ssh -i /home/xxxx/yyy/zzz/ONAPDlDK/id_rsa onap_user@10.10.10.10
is an example.
You can not log into the aks nodes as far as I know but you can kubectl exec into the pods just like any other ONAP installation once you set KUBECONFIG as indicated in your deployment.txt file.
Sergey Kolpakov
thanks, but can't find deployment.txt at least in the files here
https://gerrit.onap.org/r/integrationBrian Freeman
its dynamically created when you run cloud.sh (integration/deployment/aks/cloud.sh) - my instructions are for the that deployment method in azure.
Sergey Kolpakov
thanks for your comments, finally I reset the password for VM via azure portal GUI and login via SSH with this new login and then run sudo su and it works, then I deployed onap from ./oom/scripts/deploy-aee.sh
Brian Freeman
I dont recognize deploy-aee.sh so I probably have not provided you with guidance that is relevant to the path you are on. This page is from Beijing release that last was tested i Casablanca as far as I know. We mainly use integration/deployment/aks/cloud.sh for deployment in Azure since it also deploys a Devstack for instantiation testing.
Sergey Kolpakov
Actually it was my first time, I mean ONAP deploy and so I was trying to follow this guide above and it contradicts a bit with what they do in video where they uses deploy-aee.sh for deploying.
But now I have other issue, I can't access ONAP portal, do you know is there any basic hints how to find the root cause of the problem?
Brian Freeman
which version of onap are you running ? portal access has changed alot since Beijing (and I assume portal is up and passing healtchecks)
Sergey Kolpakov
I deployed the version which is available in github, the link is on this page above.
I run healthcheck (see below failed tests) and some test are failed, also some ports are not running (see below) but I didn't find any guide which tests are critical to pass and what to do if not, the same with ports info.
I run also
kubectl get svc -n onap | grep portal
got this
portal-app LoadBalancer 10.43.179.217 52.138.136.244
when I try to access 52.138.136.244 or via DNS name I can't get the response from server and I added these addresses into the hosts file. Also I didn't get why IP is 10.43.179.217 and when I see this host via Rancher GUI there is the same public IP 52.138.136.244 but different IP for loadbalancer container 10.42.206.22
btw is there any documentation for ONAP release with the list of all containers per each node with high level description what does this or that container
HEALTHCHECK
Basic AAF Health Check | FAIL |
Test timeout 1 minute exceeded.
Basic AAF SMS Health Check | FAIL |
500 != 200
Basic DCAE Health Check | FAIL |
500 != 200
Basic SDC Health Check | FAIL |
None != UP
OpenECOMP ETE.Robot.Testsuites.Health-Check :: Testing ecomp compo... | FAIL |
43 critical tests, 39 passed, 4 failed
43 tests total, 39 passed, 4 failed
OpenECOMP ETE.Robot.Testsuites | FAIL |
43 critical tests, 39 passed, 4 failed
43 tests total, 39 passed, 4 failed
OpenECOMP ETE.Robot | FAIL |
43 critical tests, 39 passed, 4 failed
43 tests total, 39 passed, 4 failed
OpenECOMP ETE | FAIL |
43 critical tests, 39 passed, 4 failed
43 tests total, 39 passed, 4 failed
--- PORTS ---
beijing-aaf-aaf-oauth-7fc564b797-pj9fw 0/1 CrashLoopBackOff 21 1h
beijing-aaf-aaf-service-6d748ffc7-z7kn6 0/1 CrashLoopBackOff 21 1h
beijing-appc-appc-dgbuilder-668495c8c7-wp6gz 0/1 CrashLoopBackOff 20 1h
beijing-sdnc-sdnc-ansible-server-f8bc55468-zspxt 0/1 Error 20 1h
beijing-sdnc-sdnc-dgbuilder-6ccbd8cb5c-fgj9n 0/1 CrashLoopBackOff 19 1h
dep-service-change-handler-6bd4875b5d-2bk87 0/1 CrashLoopBackOff 19 1h
Brian Freeman
I dont think the team that created that fork back in 2018 is supporting it. In any case Beijing code will have expired certificates and other problems.
I would use one of the supported deployment method on onap.readthedocs.io based on frankfurt. The aks method works quite well in azure. We use azure daily as one of the environments in our CI chain. In your results AAF failed will be a show stopper for several components. WRT to IP addresses there are multiple internal net10 ip addresses assigned by kubernetes which you should not be us foingr portal access. Only the external IP addresses matter to the outside world. I didnt think Beijing portal used a load balancer setup (or at least I remember it being difficult to setup) so that is another reason to move to Frankfurt which is about to be released.
Sergey Kolpakov
Ok, got it.
For Frankfurt release the azure VM setup is the same?
Sergey Kolpakov
Sergey Kolpakov
or its in oom clone from git?
Brian Freeman
look at the deployment file - there are instructuions on how to use the ssh key to login to the VM's. sudo should be active for the onap_user account.
Yashvanth Honnegowda
We need to upgrade the EL ALTO release on Azure instance, please let me know is anyone tried EL ALTO on azure ? if yes please let me know the procedure because we are having ARM templet for beijing release, we dont have ARM templet for future release.. please clarify
Yashvanth Honnegowda
root@k8s-host-d2se0:/home/ubuntu# kubectl get svc -n onap | grep portal
portal-app LoadBalancer 10.43.51.198 <pending> 8989:30215/TCP,8006:30213/TCP,8010:30214/TCP,8443:30225/TCP 4d5h
We upgraded the ELALTP version on Azure but load balancer IP is showing pending, please let me know how to resolve this issue...